
Competencia:
Web 2.0
Contenidos:
- Wikis
- Aplicaciones en linea
- Redes Sociales
- Depositos Multimedia
- Buscadores
- Recomendadores de Contenido
- Periodicos Populares
- Agregadores
- Web Blogs
Web 2.0
Definición de Web 2.0
La
Web 2.0 no es más que la evolución de la Web o Internet en el que
los usuarios dejan de ser usuarios pasivos para convertirse en
usuarios activos, que participan y contribuyen en el contenido de
la red siendo capaces de dar soporte y formar parte de una sociedad
que se informa, comunica y genera conocimiento.

Introducción a la web 2.0
Tim
Berners-Lee y Robert Cailliau crearon la web alrededor de 1990,
durante estas dos últimas décadas ha sufrido una evolución
extraordinaria y asombrosa, apareciendo en 2004 el concepto de Web
2.0 fruto de esta evolución de la tecnología.
Los
teóricos de la aproximación a la Web 2.0 piensan que el
uso de la web está orientado a la interacción y redes sociales,
que pueden servir contenido que explota los efectos de las redes,
creando o no webs interactivas y visuales. Es decir, los sitios Web
2.0 actúan más como puntos de encuentro o webs dependientes de
usuarios, que como webs tradicionales.
Origen del término
El término fue utilizado por primera vez por Darcy DiNucci en 1999, en su artículo "Fragmented future",3 aunque no fue hasta 2004 cuando Tim O'Reilly lo hizo popular. El término acuñado por Darcy DiNucci fue popularizado más tarde por Dale Dougherty de O'Reilly Media en una tormenta de ideas con Craig Cline de MediaLive para desarrollar ideas para una conferencia. Dougherty sugirió que la web estaba en un renacimiento, con reglas que cambiaban y modelos de negocio que evolucionaban. Dougherty puso ejemplos — "DoubleClick era la Web 1.0; AdSense es la Web 2.0. Ofoto es Web 1.0; Flickr es Web 2.0." — en vez de definiciones, y reclutó a John Battelle para dar una perspectiva empresarial, y O'Reilly Media, Battelle, y MediaLive lanzó su primera conferencia sobre la Web 2.0 en octubre de 2004. La segunda conferencia se celebró en octubre de 2005.
En
2005, Tim O'Reilly definió el concepto de Web 2.0. Un mapa mental
elaborado por Markus Angermeier resume la relación del término
Web 2.0 con otros conceptos. En su conferencia, O'Reilly, Battelle
y Edouard resumieron los principios clave que creen que
caracterizan a las aplicaciones web 2.0: la comunidad como
plataforma; efectos de red conducidos por una "arquitectura de
participación"; innovación y desarrolladores independientes;
pequeños modelos de negocio capaces de redifundir servicios y
contenidos; el perpetuo beta; software por encima de un solo
aparato.
En
general, cuando mencionamos el término Web 2.0 nos referimos a una
serie de aplicaciones y páginas de Internet que utilizan la
inteligencia colectiva (concepto de software social) para
proporcionar servicios interactivos en red.
Características
La
Web 2.0 se caracteriza principalmente por la participación del
usuario como contribuidor activo y no solo como espectador de los
contenidos de la Web (usuario pasivo). Esto queda reflejado en
aspectos como:
- El auge de los blogs.
- El auge de las redes sociales.
- Las webs creadas por los usuarios, usando plataformas de auto-edición.
- El contenido agregado por los usuarios como valor clave de la Web.
- El etiquetado colectivo (folcsonomía, marcadores sociales...).
- La importancia del long tail.
- El beta perpetuo: la Web 2.0 se inventa permanentemente.
- Aplicaciones web dinámicas.
Servicios asociados
Para
compartir en la Web 2.0 se utilizan una serie de herramientas,
entre las que se pueden destacar:
- Blogs: Un blog es un espacio web personal en el que su autor (puede haber varios autores autorizados) puede escribir cronológicamente artículos, noticias...(con imágenes videos y enlaces), pero además es un espacio colaborativo donde los lectores también pueden escribir sus comentarios a cada uno de los artículos (entradas/post) que ha realizado el autor. La blogosfera es el conjunto de blogs que hay en internet. Como servicio para la creación de blogs destacan Wordpress.com y Blogger.com
- Wikis: En hawaiano "wiki" significa: rápido, informal. Una wiki es un espacio web corporativo, organizado mediante una estructura hipertextual de páginas (referenciadas en un menú lateral), donde varias personas elaboran contenidos de manera asíncrona. Basta pulsar el botón "editar" para acceder a los contenidos y modificarlos. Suelen mantener un archivo histórico de las versiones anteriores y facilitan la realización de copias de seguridad de los contenidos. Hay diversos servidores de wikis gratuitos.
- Redes sociales: Sitios web donde cada usuario tiene una página donde publica contenidos y se comunica con otros usuarios. Ejemplos: Facebook, Twitter, Tuenti, Hi5, Myspace, etc. También existen redes sociales profesionales, dirigidas a establecer contactos dentro del mundo empresarial (LinkedIn, Xing, eConozco, Neurona...).
- Entornos para compartir recursos: Entornos que nos permiten almacenar recursos o contenidos en Internet, compartirlos y visualizarlos cuando nos convenga. Constituyen una inmensa fuente de recursos y lugares donde publicar materiales para su difusión mundial. Existen de diversos tipos, según el contenido que albergan o el uso que se les da:
- Documentos: Google Drive y Office Web Apps (SkyDrive), en los cuales podemos subir nuestros documentos, compartirlos y modificarlos.
- Videos: Youtube, Vimeo, Dailymotion, Dalealplay... Contienen miles de vídeos subidos y compartidos por los usuarios.
- Fotos: Picasa, Flickr, Instagram... Permiten disfrutar y compartir las fotos también tenemos la oportunidad de organizar las fotos con etiquetas, separándolas por grupos como si fueran álbumes, podemos seleccionar y guardar aparte las fotos que no queremos publicar.
- Agregadores de noticias: Digg, Reddit, Menéame, Divoblogger... Noticias de cualquier medio son agregadas y votadas por los usuarios.
- Almacenamiento online: Dropbox, Google Drive, SkyDrive
- Presentaciones: Prezi, Slideshare.
- Plataformas educativas
- Aulas virtuales (síncronas)
- Encuestas en línea
Tecnología de la web 2.0
Se
puede decir que una web está construida usando tecnología de la
Web 2.0 si posee las siguientes características:
- Técnicas:
- CSS, marcado XHTML válido semánticamente y Microformatos
- Técnicas de aplicaciones ricas no intrusivas (como AJAX)
- Java Web Start
- Redifusión/Agregación de datos en RSS/ATOM
- URLs sencillas con significado semántico
- Soporte para postear en un blog
- JCC y APIs REST o XML
- JSON
- Algunos aspectos de redes sociales
- Mashup (aplicación web híbrida)
- General:
- El sitio debe estar listo para la entrada de cualquier persona
- El sitio no debe actuar como un "jardín sin cosechar inminentemente": la información debe poderse introducir y extraer fácilmente
- Los usuarios deberían controlar su propia información
- Basada exclusivamente en la Web: los sitios Web 2.0 con más éxito pueden ser utilizados enteramente desde un navegador
- La existencia de links es requisito imprescindible
Software de servidor
La
redifusión solo se diferencia nominalmente de los métodos de
publicación de la gestión dinámica de contenido, pero los
servicios Web requieren normalmente un soporte de bases de datos y
flujo de trabajo mucho más robusto y llegan a parecerse mucho a la
funcionalidad de Internet tradicional de un servidor de
aplicaciones. El enfoque empleado hasta ahora por los fabricantes
suele ser bien un enfoque de servidor universal, el cual agrupa la
mayor parte de la funcionalidad necesaria en una única plataforma
de servidor, o bien un enfoque plugin de servidor Web con
herramientas de publicación tradicionales mejoradas con interfaces
API y otras herramientas. Independientemente del enfoque elegido,
no se espera que el camino evolutivo hacia la Web 2.0 se vea
alterado de forma importante por estas opciones.
Relaciones con otros conceptos
La
web 1.0 principalmente trata lo que es el estado estático, es
decir los datos que se encuentran en ésta no pueden cambiar, se
encuentran fijos, no varían, no se actualizan.
| Web 1.0 | Web 2.0 |
|---|---|
| DoubleClick | AdSense |
| Ofoto | Flickr |
| Terratv | YouTube |
| Akamai | BitTorrent |
| Napster | Mp3.com |
| Enciclopedia Británica | Wikipedia |
| webs personales | blogging |
| Páginas vistas | coste por clic |
| screen scraping | servicios web |
| Publicación | participación |
| Sistema de gestión de contenidos | wiki |
| hotmail | Gmail AOL |
| directorios (taxonomía) | etiquetas (folcsonomía) |
| stickiness | redifusión |
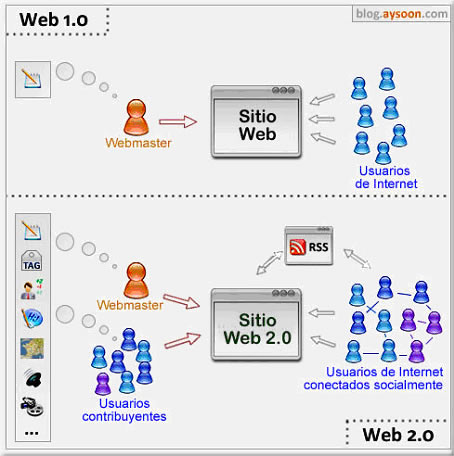 |
| Evolucion de la web 1.0 a la web 2.0 |
Comparación con la Web Semántica
En ocasiones se ha relacionado el término Web 2.0 con el de Web semántica.4 Sin embargo ambos conceptos, corresponden más bien a estados evolutivos de la web, y la Web semántica correspondería en realidad a una evolución posterior, a la Web 3.0 o web inteligente. La combinación de sistemas de redes sociales como Facebook, Twitter, FOAF y XFN, con el desarrollo de etiquetas (o tags), que en su uso social derivan en folcsonomías, así como el plasmado de todas estas tendencias a través de blogs y wikis, confieren a la Web 2.0 un aire semántico sin serlo realmente. Sin embargo, en el sentido más estricto para hablar de Web semántica, se requiere el uso de estándares de metadatos como Dublin Core y en su forma más elaborada de ontologías y no de folcsonomías. De momento, el uso de ontologías como mecanismo para estructurar la información en los programas de blogs es anecdótico y solo se aprecia de manera incipiente en algunos wiki.5Consecuencias de la Web 2.0
 |
| Herramientas de la Web 2.0 |
Debilidades de la Web 2.0
Cada
uno de los internautas de la Web 2.0 son “autores” de los
contenidos que vuelcan en la Red, siempre que se trate de
“creaciones originales”.Sin embargo, nada obsta para que una
obra de “nueva creación” pueda incluir, total o parcialmente,
una obra previa de otro autor. Esto es lo que se denomina “obra
compuesta”.Para evitar problemas tipificados legalmente sería
necesario contar con la autorización del autor de la obra previa o
bien usar la misma dentro de una de las excepciones reconocidas en
la propia Ley (ver Ley de Propiedad Intelectual).Ser autor de una
web 2.0 supone, ni más ni menos, el tener la plena disposición y
el derecho exclusivo a la explotación de dicha obra, sin más
limitaciones que las establecidas en la Ley.Por tanto, la primera
consecuencia jurídica de la Web 2.0 es que todos, más que nunca,
somos “propietarios” de Internet y, en todo caso, de los
contenidos concretos que creamos e introducimos diariamente en
servicios como Blogger, Flickr, Facebook, Twitter o el ya
mencionado Youtube.Es decir, cada vez más, la Ley de Propiedad
Intelectual no sólo se nos aplica para limitar nuestro acceso y
uso de contenidos ajenos sino también para proteger y defender
nuestros propios contenidos volcados en la Red.Falta implementar
estrategias de seguridad informática, el constante intercambio de
información y la carencia de un sistema adecuado de seguridad ha
provocado el robo de datos e identidad generando pérdidas
económicas y propagación de virus.La seguridad es fundamental en
la tecnología, las empresas invierten en la seguridad de sus datos
y quizás el hecho de que la web aún no sea tan segura, crea un
leve rechazo a la transición de algunas personas con respecto a la
automatización de sus sistemas.
Agregador
Un
lector
o recopilador de contenidos (también
conocido como agregador,
agregador
de noticias
o lector
de RSS)
es un tipo de software para suscribirse a fuentes de noticias en
formatos RSS, Atom y otros derivados de XML como RDF/XML. El
agregador reúne las noticias o historias publicadas en los sitios
con redifusión web elegidos, y muestra las novedades o
modificaciones que se han producido en esas fuentes web; es decir,
avisa de qué webs han incorporado contenido nuevo desde nuestra
última lectura y cuál es ese contenido. Esta información es la que
se conoce como fuente web.
Un
agregador es muy similar en sus presentaciones a los anteriores
lectores de noticias (client newsreaders/NNTP), pero la tecnología
XML y el web semántico los ha hecho más populares. Hoy en día, una
enorme cantidad de blogs y sitios web ofrecen sus actualizaciones,
que pueden ser fácilmente reunidas y administradas en un solo punto,
como es el caso del servicio My Yahoo! o el de Netvibes.
Filtrado en la alimentación
Uno
de los problemas con los agregadores de noticias es que el volumen de
los artículos a veces puede ser abrumador, sobre todo cuando el
usuario tiene muchas suscripciones Web. Como solución, muchos de los
lectores de feeds permiten a los usuarios etiquetar cada fuente con
una o más palabras clave que pueden utilizarse para ordenar y
filtrar los artículos disponibles en categorías fácilmente
navegables. Otra opción es la importación del perfil de atención
del usuario (en lenguaje APML) para filtrar los elementos según su
relevancia para los intereses del usuario.
Aplicación web
En la ingeniería de software se denomina aplicación web a aquellas herramientas que los usuarios pueden utilizar accediendo a un servidor web a través de Internet o de una intranet mediante un navegador. En otras palabras, es una aplicación software que se codifica en un lenguaje soportado por los navegadores web en la que se confía la ejecución al navegador.

Es
importante mencionar que una página Web puede contener elementos
que permiten una comunicación activa entre el usuario y la
información. Esto permite que el usuario acceda a los datos de
modo interactivo, gracias a que la página responderá a cada una
de sus acciones, como por ejemplo rellenar y enviar formularios,
participar en juegos diversos y acceder a gestores de base de datos
de todo tipo.
Antecedentes
En
los primeros tiempos de la computación cliente-servidor, cada
aplicación tenía su propio programa cliente que servía como
interfaz de usuario que tenía que ser instalado por separado en
cada ordenador personal de cada usuario. El cliente realizaba
peticiones a otro programa -el servidor- que le daba respuesta. Una
mejora en el servidor, como parte de la aplicación, requería
normalmente una mejora de los clientes instalados en cada ordenador
personal, añadiendo un coste de soporte técnico y disminuyendo la
productividad.
A
diferencia de lo anterior, las aplicaciones web generan
dinámicamente una serie de páginas en un formato estándar, como
HTML o XHTML, soportados por los navegadores web comunes. Se
utilizan lenguajes interpretados en el lado del cliente,
directamente o a través de plugins tales como JavaScript, Java,
Flash, etc., para añadir elementos dinámicos a la interfaz de
usuario. Generalmente cada página web en particular se envía al
cliente como un documento estático, pero la secuencia de páginas
ofrece al usuario una experiencia interactiva. Durante la sesión,
el navegador web interpreta y muestra en pantalla las páginas,
actuando como cliente para cualquier aplicación web.
Interfaz
Las
interfaces web tienen ciertas limitaciones en las funcionalidades
que se ofrecen al usuario. Hay funcionalidades comunes en las
aplicaciones de escritorio como dibujar en la pantalla o
arrastrar-y-soltar que no están soportadas por las tecnologías
web estándar. Los desarrolladores web generalmente utilizan
lenguajes interpretados (scripts) en el lado del cliente para
añadir más funcionalidades, especialmente para ofrecer una
experiencia interactiva que no requiera recargar la página cada
vez (lo que suele resultar molesto a los usuarios). Recientemente
se han desarrollado tecnologías para coordinar estos lenguajes con
las tecnologías en el lado del servidor. Como ejemplo, AJAX es una
técnica de desarrollo web que usa una combinación de varias
tecnologías.
Consideraciones técnicas
Una
ventaja significativa es que las aplicaciones web deberían
funcionar igual independientemente de la versión del sistema
operativo instalado en el cliente. En vez de crear clientes para
Windows, Mac OS X, GNU/Linux y otros sistemas operativos, la
aplicación web se escribe una vez y se ejecuta igual en todas
partes. Sin embargo, hay aplicaciones inconsistentes escritas con
HTML, CSS, DOM y otras especificaciones estándar para navegadores
web que pueden causar problemas en el desarrollo y soporte de estas
aplicaciones, principalmente debido a la falta de adhesión de los
navegadores a dichos estándares web (especialmente versiones de
Internet Explorer anteriores a la 7.0). Adicionalmente, la
posibilidad de los usuarios de personalizar muchas de las
características de la interfaz (tamaño y color de fuentes, tipos
de fuentes, inhabilitar Javascript) puede interferir con la
consistencia de la aplicación web.
Otra
aproximación es utilizar Adobe Flash Player o Java applets para
desarrollar parte o toda la interfaz de usuario. Como casi todos
los navegadores incluyen soporte para estas tecnologías
(usualmente por medio de plug-ins), las aplicaciones basadas en
Flash o Java pueden ser implementadas con aproximadamente la misma
facilidad. Dado que ignoran las configuraciones de los navegadores,
estas tecnologías permiten más control sobre la interfaz, aunque
las incompatibilidades entre implementaciones Flash o Java puedan
crear nuevas complicaciones, debido a que no son estándares. Por
las similitudes con una arquitectura cliente-servidor, con un
cliente "no ligero", existen discrepancias sobre el hecho
de llamar a estos sistemas “aplicaciones web”; un término
alternativo es “Aplicación Enriquecida de Internet”.
Estructura de las aplicaciones web
Aunque
existen muchas variaciones posibles, una aplicación web está
normalmente estructurada como una aplicación de tres-capas. En su
forma más común, el navegador web ofrece la primera capa, y un
motor capaz de usar alguna tecnología web dinámica, por ejemplo:
PHP, Java Servlets o ASP, ASP.NET, CGI, ColdFusion, embPerl, Python
o Ruby on Rails que constituye la capa intermedia. Por último, una
base de datos constituye la tercera y última capa.
El
navegador web manda peticiones a la capa intermedia que ofrece
servicios valiéndose de consultas y actualizaciones a la base de
datos y a su vez proporciona una interfaz de usuario.
Uso empresarial
Una
estrategia que está emergiendo para las empresas proveedoras de
software consiste en proveer acceso vía web al software. Para
aplicaciones previamente distribuidas, como las aplicaciones de
escritorio, se puede optar por desarrollar una aplicación
totalmente nueva o simplemente por adaptar la aplicación para ser
usada con una interfaz web. Estos últimos programas permiten al
usuario pagar una cuota mensual o anual para usar la aplicación,
sin necesidad de instalarla en el ordenador del usuario. A esta
estrategia de uso se la denomina Software como servicio y a las
compañías desarrolladoras se les denomina Proveedores de
Aplicaciones de Servicio (ASP por sus siglas en inglés), un modelo
de negocio que está atrayendo la atención de la industria del
software.
Ventajas
-
Ahorra tiempo: Se pueden realizar tareas sencillas sin
necesidad de descargar ni instalar ningún programa.
-
No hay problemas de compatibilidad: Basta tener un navegador
actualizado para poder utilizarlas.
-
No ocupan espacio en nuestro disco duro.
-
Actualizaciones inmediatas: Como el software lo gestiona el
propio desarrollador, cuando nos conectamos estamos usando siempre
la última versión que haya lanzado.
-
Consumo de recursos bajo: Dado que toda (o gran parte) de la
aplicación no se encuentra en nuestro ordenador, muchas de las
tareas que realiza el software no consumen recursos nuestros porque
se realizan desde otro ordenador.
-
Multiplataforma: Se pueden usar desde cualquier sistema
operativo porque sólo es necesario tener un navegador.
-
Portables:
Es independiente del ordenador donde se utilice (un PC de
sobremesa, un portátil...) porque se accede a través de una
página web (sólo es necesario disponer de acceso a Internet). La
reciente tendencia al acceso a las aplicaciones web a través de
teléfonos móviles requiere sin embargo un diseño específico de
los ficheros CSS para no dificultar el acceso de estos usuarios.
-
La disponibilidad suele ser alta porque el servicio se
ofrece desde múltiples localizaciones para asegurar la continuidad
del mismo.
-
Los virus no dañan los datos porque éstos están guardados
en el servidor de la aplicación.
-
Colaboración: Gracias a que el acceso al servicio se
realiza desde una única ubicación es sencillo el acceso y
compartición de datos por parte de varios usuarios. Tiene mucho
sentido, por ejemplo, en aplicaciones online de calendarios u
oficina.
-
Los navegadores ofrecen cada
vez más y mejores funcionalidades
para crear aplicaciones web ricas (RIAs).
Inconvenientes
-
Habitualmente ofrecen menos
funcionalidades que las aplicaciones de escritorio.
Se debe a que las funcionalidades que se pueden realizar desde un
navegador son más limitadas que las que se pueden realizar desde
el sistema operativo. Pero cada vez los navegadores están más
preparados para mejorar en este aspecto. La aparición de HTML 5
representa un hito en este sentido. Es posible añadir
funcionalidades a estas aplicaciones gracias al uso de Aplicaciones
de Internet Enriquecidas.
-
La
disponibilidad depende de un tercero,
el proveedor de la conexión a internet o el que provee el enlace
entre el servidor de la aplicación y el cliente. Así que la
disponibilidad del servicio está supeditada al proveedor.
Diferencia entre aplicación web y aplicación de internet enriquecida (RIA)
Las
aplicaciones web se ejecutan nativamente desde el navegador.
Pero existen algunas aplicaciones que funcionan desde el navegador
pero además requieren la instalación de un software en el
ordenador para poder utilizarse. Estas aplicaciones se denominan
Aplicaciones de Internet Ricas. El motivo de usar este software
adicional es que hay muchas funcionalidades que los navegadores no
pueden ofrecer, y él enriquece
a las aplicaciones web ofreciendo dichas funcionalidades.
.
Ejemplos
de funcionalidades que pueden ofrecer los programas online gracias
al uso de software instalado:
-
Procesamiento de imágenes
-
Captura de imágenes
Lenguajes de programación
Existen
numerosos lenguajes de programación empleados para el desarrollo
de aplicaciones web en el servidor, entre los que destacan:
- PHP
- Java, con sus tecnologías Java Servlets y JavaServer Pages (JSP)
- Javascript
- Perl
- Ruby
- Python
- C# y Visual Basic con sus tecnologías ASP/ASP.NET
También
son muy utilizados otros lenguajes o arquitecturas que no son
propiamente lenguajes de programación, como HTML o XML.
Se
utilizan para servir los datos adecuados a las necesidades del
usuario, en función de como hayan sido definidos por el dueño de
la aplicación. Los datos se almacenan en alguna base de datos
estándar.
Depositos
Un repositorio,
depósito
o archivo
es un sitio centralizado donde se almacena y mantiene información
digital, habitualmente bases de datos o archivos informáticos.
Características generales
Los datos almacenados en
un repositorio pueden distribuirse a través de una red
informática, como Internet, o de un medio físico, como un disco
compacto. Pueden ser de acceso público o estar protegidos y
necesitar de una autentificación previa. Los repositorios más
conocidos son los de carácter académico e institucional. Los
repositorios suelen contar con sistemas de respaldo (copia de
seguridad) y mantenimiento preventivo y correctivo, lo que hace que
la información se pueda recuperar en el caso que la máquina quede
inutilizable.
Depositar no debe
confundirse con publicar. El depósito en los repositorios es una
manera de comunicar públicamente los trabajos de los
investigadores, aumentando su difusión: los autores ponen
disponibles en acceso abierto una versión
de los artículos que han publicado en revistas, tradicionales o de
acceso abierto.
Tipología
Repositorios tipo
1: repositorios que almacenan los contenidos y presentan un
número limitado de enlaces a contenidos externos. Esta
categoría comprendería, entre otros, a los siguientes:
Exploratorium Digital Library, Illumina Digital Library (NSDL),
Lola (Learning Objects Learning Activities), MLX (Maricopa Learning
Exchange)
Repositorios tipo
2: repositorios que no almacenan contenidos, sino que
referencian contenidos externos. En esta categoría estarían,
entre otros: Careo (Campus Alberta Repository of Educational
Objects), Citidel (Computing and Information Technology Interactive
Digital Educational Library), Merlot.
Repositorios tipo
3: repositorios "híbridos" que albergan tanto
contenidos como vínculos. Dentro de esta categoría se
situarían: ARIADNE (European Knowledge Pool System), ConneXions,
EdNa (Educational Network of Australia) y NSDL (National Science
Digital Library)
Evolución histórica
En el 2002, el
desarrollo de repositorios institucionales emergió como una
estrategia nueva que permite a las universidades aplicar un control
sistemático que acelere los cambios que ocurren en la comunicación
del estudiante, publicando contenido académico a través de medios
digitales.
Las tendencias de la
tecnología y los esfuerzos en el desarrollo del software hicieron
posible esta estrategia. El pensamiento de la preservación digital
sobre los últimos cinco años ha avanado al punto donde se
reconocen indudablemente necesarios. El desarrollo de las
colecciones de documentos ha demostrado al público las
maneras en las cuales la red puede ayudar de manera favorable para
la educación.
El Instituto de
Tecnología de Massachusetts (MIT) en colaboración con la
corporación Hewlett Packard, desarrollaron una herramienta para
crear un repositorio institucional llamado Dspace. En 2003, con el
financiamiento de la Fundación Andrew W. Mellon y otras fuentes,
un número de instituciones alrededor del mundo incorporaron sus
investigaciones a través de Dspace del MIT (Lynch 2003). Sin
embargo el software del MIT no es la única opción disponible,
existen un gran núnero de instituciones que han desarrollado sus
propias herramientas para la creación de un repositorio
institucional.
En España el desarrollo
de los mismos está en una etapa emergente y los datos varían en
cortos periodos de tiempo, como se deduce de las cifras de los
últimos dos años. Este crecimiento responde a la expansión que
el movimiento open access en favor del acceso abierto a la
producción científica, ha cobrado en España, que se traduce, en
proyectos, no sólo relacionados con la creación de proveedores de
datos, sino también con proveedores de servicios sobre
repositorios. De forma cuantitativa, en mayo de 2006 (Melero, 2006)
había registrados en ROAR2(Registry of Open Access Repositories)
13 repositorios y 5 en OpenDOAR3(Directory of Open Acces
Repositories), un año después, las cifras eran de 27 y 12
en los directorios mencionados respectivamente, y entonces ya
existían en fase de desarrollo algunos más que todavía no habían
sido registrados (Melero, 2007). Las diferencias en número
de repositorios entre ROAR y OpenDOAR se deben a los criterios de
inclusión de estos directorios. En ROAR, a pesar de que su nombre
indica "registro de repositorios", se incluyen otros
proveedores de datos que cumplen con el protocolo OAI-PMH como
algunas revistas open accesscuya arquitectura de ficheros también
responde a este protocolo. A pesar de ser directorios
fiables, además de esta observación también existen algunos
errores en el cómputo tal y como se detallará más adelante a la
vista de los datos extraídos con fecha de febrero de 2008. Por lo
tanto a la hora de ofrecer datos hay que verificar a qué archivos
responden esas cifras para no evitar arrastrar errores, como se
deduce del análisis hecho durante la redacción de este artículo.
La información extraída de estos dos directorios se han
contrastado con el censo recogido en la web Busca repositorios
mantenida y elaborada por esta autora, cuyos criterios de inclusión
son repositorios de acceso abierto de instituciones de carácter
académico de investigación o culturales. Cuantitativamente el
contenido de los mismos se ha comparado frente al recolector
español de recursos digitales OAI, RECOLECTA y también por
consulta directa en los portales de cada uno de ellos.
Repositorios científicos
Unión Europea
PubMed Central:
Se trata de un repositorio temático con un enorme éxito lo cual
ha dado pie a que se haya creado una red llamada PMI International
con el objeto de establecer archivos abiertos en colaboración con
instituciones locales de cada país. Se encuentra especializado en
Medicina. Se ha convertido en una fuente de referencia para
investigadores de todo el mundo.
DSpace@Cambridge:
Se trata de un servicio de la Universidad de Cambrigde gestionado
por la biblioteca y el servicio de informática. Ofrece artículos,
tesis, informes técnicos en diferentes formatos. Su objetivo es
preservar y difundir los materiales digitales creados por personas
vinculadas o no a la universidad.
Motor de búsqueda
Un
motor
de búsqueda,
también conocido como buscador,
es un sistema informático que busca archivos almacenados en
servidores web gracias a su «spider»
(o Web crawler). Un ejemplo son los buscadores de Internet (algunos
buscan únicamente en la web, pero otros lo hacen además en
noticias, servicios como Gopher, FTP, etc.) cuando se pide
información sobre algún tema. Las búsquedas se hacen con palabras
clave o con árboles jerárquicos por temas; el resultado de la
búsqueda es un listado de direcciones web en los que se mencionan
temas relacionados con las palabras clave buscadas.
 |
| Algunos motores de Busqueda |
Clasificación
Se
pueden clasificar en dos tipos:
- Índices temáticos: Son sistemas de búsqueda por temas o categorías jerarquizados (aunque también suelen incluir sistemas de búsqueda por palabras clave). Se trata de bases de datos de direcciones Web elaboradas "manualmente", es decir, hay personas que se encargan de asignar cada página web a una categoría o tema determinado.
- Motores de búsqueda: Son sistemas de búsqueda por palabras clave. Son bases de datos que incorporan automáticamente páginas web mediante "robots" de búsqueda en la red.
Clases de buscadores
Buscadores jerárquicos (Arañas o Spiders)
- Recorren las páginas recopilando información sobre los contenidos de las páginas. Cuando se busca una información en los motores, ellos consultan su base de datos y presentan resultados clasificados por su relevancia. De las webs, los buscadores pueden almacenar desde la página de entrada, a todas las páginas que residan en el servidor.

- Si se busca una palabra, por ejemplo, “ordenadores”. En los resultados que ofrecerá el motor de búsqueda, aparecerán páginas que contengan esta palabra en alguna parte de su texto.
- Si consideran que un sitio web es importante para el usuario, tienden a registrarlas todas. Si no la consideran importante, sólo almacenan una o más páginas.
- Cada cierto tiempo, los motores revisan los sitios, para actualizar los contenidos de su base de datos, por tanto puede que los resultados de la búsqueda estén desactualizados.
- Los buscadores jerárquicos tienen una colección de programas simples y potentes con diferentes cometidos. Se suelen dividir en tres partes. Los programas que exploran la red -arañas (spiders)-, los que construyen la base de datos y los que utiliza el usuario, el programa que explota la base de datos.
- Si se paga, se puede aparecer en las primeras páginas de resultados, aunque los principales buscadores delimitan estos resultados e indican al usuario que se trata de resultados esponsorizados o patrocinados. Hasta el momento, aparentemente, esta forma de publicidad es indicada explícitamente. Los buscadores jerárquicos se han visto obligados a comercializar este tipo de publicidad para poder seguir ofreciendo a los usuarios el servicio de forma gratuita.
Directorios
Una
tecnología barata, ampliamente utilizada por gran cantidad de
scripts en el mercado. No se requieren muchos recursos de
informática. En cambio, se requiere más soporte humano y
mantenimiento.
- Los algoritmos son mucho más sencillos, presentando la información sobre los sitios registrados como una colección de directorios. No recorren los sitios web ni almacenan sus contenidos. Solo registran algunos de los datos de nuestra página, como el título y la descripción que se introduzcan al momento de registrar el sitio en el directorio.
- Los resultados de la búsqueda, estarán determinados por la información que se haya suministrado al directorio cuando se registra el sitio. En cambio, a diferencia de los motores, son revisadas por operadores humanos, y clasificadas según categorías, de forma que es más fácil encontrar páginas del tema de nuestro interés.
- Más que buscar información sobre contenidos de la página, los resultados serán presentados haciendo referencia a los contenidos y temática del sitio.
- Su tecnología es muy barata y sencilla.
Ejemplos
de directorios: Antiguos directorios, Open Directory Project, Yahoo!,
Terra (antiguo Olé). Ahora, ambos utilizan tecnología de búsqueda
jerárquica, y Yahoo! conserva su directorio. Buscar Portal, es un
directorio, y la mayoría de motores hispanos son
directorios.
 |
| Metabuscadores en la web |
Metabuscador
Permite
lanzar varias búsquedas en motores seleccionados respetando el
formato original de los buscadores. Lo que hacen, es realizar
búsquedas en auténticos buscadores, analizan los resultados de la
página y presentan sus propios resultados, según un orden definido
por el sistema estructural del metabuscador. Metacrawler, Aleyares
son ejemplos de este tipo de buscador.
FFA - Enlaces gratuitos para todos
FFA
(acrónimo del inglés "Free For All"), Cualquiera
puede inscribir su página durante un tiempo limitado en estos
pequeños directorios. Los enlaces no son permanentes.
Buscadores verticales
Los
buscadores
verticales
o motores
de búsqueda temáticos
son buscadores especializados en un sector concreto, lo que les
permite analizar la información con mayor profundidad, disponer de
resultados más actualizados y ofrecer al usuario herramientas de
búsqueda avanzadas. Es importante resaltar que utilizan índices
especializados, para, de este modo, acceder a la información de una
manera más específica y fácil. Algunos ejemplos de estos
buscadores son: http://www.trovit.com, Nestoria, Wolfram Alpha.
Existen
distintos tipos de estos buscadores, algunos son especializados en
una rama de una ciencia, y algunos abarcan todo tipo de materias.
También hay motores de búsqueda que solo entregan resultados sobre
música, ropa o distintos temas.
Historia
El
primer buscador fue "Wandex", un índice (ahora
desaparecido) realizado por la World Wide Web Wanderer, un robot
desarrollado por Mattew Gray en el MIT, en 1993. Otro de los primeros
buscadores, Aliweb, también apareció en 1993 y todavía está en
funcionamiento. El primer motor de búsqueda de texto completo fue
WebCrawler, que apareció en 1994. A diferencia de sus predecesores,
éste permitía a sus usuarios una búsqueda por palabras en
cualquier página web, lo que llegó a ser un estándar para la gran
mayoría de los buscadores. WebCrawler fue asimismo el primero en
darse a conocer ampliamente entre el público. También apareció en
1994 Lycos (que comenzó en la Carnegie Mellon University).
Muy
pronto aparecieron muchos más buscadores, como Excite, Infoseek,
Inktomi, Northern Light y Altavista. De algún modo, competían con
directorios (o índices temáticos) populares tales como Yahoo!. Más
tarde, los directorios se integraron o se añadieron a la tecnología
de los buscadores para aumentar su funcionalidad.
Antes
del advenimiento de la Web, había motores de búsqueda para otros
protocolos o usos, como el buscador Archie, para sitios FTP anónimos
y el motor de búsqueda Verónica, para el protocolo Gopher.
En
la actualidad se aprecia una tendencia por parte de los principales
buscadores de Internet a dar el salto hacia entornos móviles creando
una nueva generación de buscadores: los buscadores móviles.
Periódicos Populares
La prensa digital: ¿un fenómeno de masas?
Durante
los últimos años, en los países desarrollados el número de
usuarios que accede de forma habitual a Internet ha aumentado
considerablemente. El abaratamiento de los ordenadores, y la
implantación casi generalizada y de bajo coste de la banda ancha han
hecho posible que Internet se convierta en una herramienta de
trabajo, comunicación y entretenimiento de uso cotidiano.
Ante
este aumento del consumo de Internet cabe preguntarse sobre la forma
en que los usuarios pasan su tiempo en la red. En el año 2003, el
46% de los usuarios de Estados Unidos concebían Internet como una
herramienta de comunicación, mientras que el 34% de los encuestados
lo utilizaba como un medio para buscar contenidos (datos facilitados
por la Online Publishers Association). En el año 2007 los resultados
fueron bien distintos. El 33% de los usuarios utilizaba la red como
un medio para comunicarse (sobre todo a través del correo
electrónico), pero el número de internautas que admitía usar
Internet como medio para acceder a contenidos había ascendido al
47%. La Online Publishers Association atribuye esta evolución al uso
generalizado de la banda ancha, que permite una descarga y
visualización de contenidos mucho más rápida y al aumento de la
cantidad de contenidos disponibles en la Web durante los últimos
años y la confianza de los usuarios hacia éstos.
A
esta tendencia también han contribuido: 1) el perfeccionamiento de
los motores de búsqueda, que facilitan a sus usuarios un acceso cada
vez más preciso a la información, y 2) la buena acogida que ha
tenido para los internautas la incorporación de contenidos
multimedia en la Web, siendo especialmente relevante el caso del
video en línea.
Entre
los distintos contenidos que pueden encontrarse en la Web ocupan un
lugar muy destacado las noticias. Según el estudio elaborado por el
Pew Internet & American Life Project , a finales del año 2007 el
71% de los encuestados aseguraba que lo que buscaba en Internet eran
noticias.
Este
aumento de consumo de noticias en la red se debe, en gran medida, al
ejercicio de adaptación al formato web que, durante los últimos
años, han llevado a cabo los medios de comunicación. Periódicos,
revistas o canales de televisión han cambiado notablemente su
actitud respecto a la Web. El temor y escepticismo originales de los
periodistas ha dado paso a una visión más práctica y dispuesta a
escuchar las demandas de la audiencia. Las páginas web de los medios
han aumentado progresivamente la cantidad de contenidos, al tiempo
que los han hecho más atractivos. Y aunque fieles a la imagen del
periódico o del canal de televisión en cuestión, sus versiones en
línea han creado un tipo de estilo y lenguaje propios pensados para
satisfacer las demandas de los nuevos usuarios en línea (Horrigan,
2006). Esto explica que un gran número de internautas haya cambiado
la pantalla de televisión por la de su ordenador o hayan dejado de
pasar las páginas de los periódicos manualmente para hacerlo a
golpe de clic. Centrándonos en el caso de la prensa digital,
diferentes estudios demuestran que los lectores en línea valoran
especialmente:
- La facilidad de acceso a la noticia: ya que en el escenario de la Web pueden encontrar fácilmente lo que buscan, y en el momento que lo desean.
- La personalización de los contenidos/informaciones recibidas: sobre todo a partir de servicios de alerta o de canales de contenido sindicado (RSS, Atom, etc.).
- La constante actualización de la información: prácticamente al minuto, de manera que pueden conocerse en todo momento las noticias de última hora.
- La confianza, valor éste que la Web ha ganado en los último años (según datos publicados en el año 2006 por Pew Research Center, el 55% de los internautas encuestados consideraba la información que encontraban en la red correcta y fiable; esta cifra no ha descendido).
A
estos factores habría que añadir la gratuidad (en casi todos los
casos) del acceso a las noticias. De hecho, muchos diarios han sabido
sacar partido de este último factor. Este ha sido el caso del
periódico The New York Times, que desde septiembre de 2007 dejó de
cobrar a los lectores en línea que querían leer sus columnas de
opinión. Como explican desde el propio periódico, el cambio de esa
política fue debido a que un gran número de lectores llegaban a sus
páginas web a través de motores de búsqueda u otro tipo de
vínculos diferentes a la propia dirección del periódico
(http://www.nytimes.com). Estos lectores indirectos empezaron a ser
considerados por este medio una oportunidad de negocio, ya que
aumentaban considerablemente el número de usuarios que visitaban sus
páginas y, en consecuencia, los beneficios generados en concepto de
publicidad.
La prensa digital y los buscadores de noticias
No
obstante, no todos los periódicos en línea consideran que los
buscadores de noticias son sus aliados. Algunos medios opinan que el
hecho de que estas herramientas faciliten enlaces directos a sus
noticias supone un perjuicio a sus ingresos por publicidad.
Argumentan que los usuarios acceden a la noticia sin visualizar las
páginas principal y de la sección en la que ésta se encuentra y,
por tanto, sin posibilidad de ver los anuncios que aparecen en ellas.
Un
claro ejemplo de esta posición es el caso de la prensa belga, que en
el año 2008 denunció a Google News. Esta denuncia terminó con una
sentencia que obligó al buscador a dejar de indexar los contenidos
de estos diarios y pagarles una indemnización de más de 40 millones
de euros, tanto por reproducir y comunicar públicamente obras
protegidas por derechos de autor, como por perjudicar los ingresos
por publicidad que perciben estos medios.
Parece
discutible que medidas de este tipo puedan beneficiar de algún modo
a los medios en línea. De hecho, podría perjudicarles seriamente
pues los contenidos indexados por los motores de búsqueda reciben un
mayor número de visitas. Esto trasladado a los medios supone un
aumento de sus ingresos en concepto de publicidad. Se ha de tener muy
presente que entre el 50% y el 90% del tráfico que recibe un sitio
web procede de los buscadores, y principalmente de Google.
Otra
cuestión, muy diferente a la anterior, y que sí podría afectar a
los medios tradicionales que se han incorporado a la Web, es el papel
que juegan los buscadores de noticias que han adoptado el rol de
medio de comunicación. Éste es el caso, por ejemplo, de Yahoo!
Noticias (http://es.noticias.yahoo.com/). Dicho buscador ha optado (a
diferencia de Google Noticias) por recuperar por defecto noticias de
agencias que él mismo ha contratado. Esto implica que, normalmente,
los usuarios acceden a las noticias sin abandonar el portal de
Yahoo!, incrementando en consecuencia los ingresos por publicidad del
mismo. De esta manera, este buscador ha dejado de actuar sólamente
como tal y se ha transformado en un portal que incluye un servicio de
noticias, mostrando así que ha sabido aprovechar su comunidad de
usuarios y las noticias que contrata para conseguir audiencia.
El acceso a la noticia en la Web
De
todo lo dicho, se puede deducir que una de las cuestiones que más ha
cambiado en cuanto a la lectura de noticias en la Web es la forma en
que los usuarios acceden a ellas. Si bien los medios de comunicación
tradicionales siguen siendo los generadores y principales
distribuidores de noticias en la web, un gran número de los usuarios
llega a ellas a través de los servicios de búsqueda de noticias.
Este es el caso de Yahoo! News , que en Estados Unidos se ha
convertido en el sitio más popular entre los usuarios para acceder a
las noticias
De
acuerdo con este gráfico, el periódico más visitado de la Web en
EE UU es The New York Times , que ocupa el quinto lugar entre los
sitios de noticias con más visitas. Los medios de comunicación
audiovisuales parecen gozar de mayor popularidad entre los usuarios
que los medios impresos (MSNBC y CNN ocupan el segundo y tercer
puesto, respectivamente). Para las cadenas de televisión el proceso
de adaptación a la Web ha sido relativamente más fácil que el
llevado a cabo por los periódicos. El alto contenido multimedia
(archivos de audio y audiovisuales) del que habitualmente disponen
estos medios ha facilitado la creación de sitios web atractivos que
permiten a los usuarios acceder al mismo tipo de contenido del que
pueden disponer en la televisión, con la ventaja añadida de poder
hacerlo cuando lo desean.
Llama
la atención el hecho de que el lugar más visitado por los usuarios
para informarse sea Yahoo! News, un buscador de noticias que ha
asumido el rol de un medio de comunicación. Determinar las claves de
su éxito no es tarea fácil, aunque la principal sí podemos
deducirla: su vasta comunidad de usuarios. Yahoo! es una empresa que
dedica grandes esfuerzos para prestar servicios en línea globales:
portal de Internet, servidor de correo, buscador, foros, directorio,
noticias, etc., y en consecuencia cuenta con una de las mayores
comunidades de la Web. Tanto es así, que durante los dos últimos
años la web de Yahoo! (http://www.yahoo.com/) ha oscilado
constantemente entre la primera y la segunda posición del ranking
mundial de sitios web más visitados (TrafficRank:
http://www.alexa.com/site/ds/top_sites) elaborado por Alexa. Por
tanto, para Yahoo! no ha sido excesivamente complicado redirigir a
muchos de sus usuarios hacia su servicio de noticias en línea.
Prensa digital y Web 2.0
Hasta
hace poco, contar con una amplia comunidad de usuarios sólo estaba
al alcance de algunos privilegiados de la Web, como el mencionado
Yahoo!. No obstante, la llegada de la Web 2.0, y muy especialmente de
las tecnologías que facilitan la comunicación social (como foros,
blogs, redes sociales, etc.), ha dotado a todos los agentes de la Web
de herramientas para:
- Atraer y fidelizar usuarios a nuestro dominio web. Esto se logra mediante la creación de sitios con contenidos fácilmente accesibles y atractivos para ellos.
- Difundir nuestros contenidos más allá de nuestro propio sitio web. Es posible conseguir este objetivo gracias a herramientas de comunicación que nos permitan buscar y acceder a potenciales usuarios de nuestros servicios en línea. Esto supone un cambio fundamental en el proceso de comunicación web porque el papel de los proveedores de contenidos, los diarios en línea entre otros, no sólo consiste en hacer que los usuarios lleguen a su sitio sino que deben desarrollar estrategias que les permitan llevar sus contenidos hasta sus usuarios.
Entre
las herramientas que ayudan a la consecución del primer objetivo se
encuentran:
- Blogs.
- Canales de contenido sindicado.
- Foros.
- Chat.
- etc.
Por
otro lado, para lograr el segundo objetivo será muy conveniente el
uso de servicios tales como:
- Redes sociales.
- Servicios para el alojamiento de contenido (multimedia).
- Servicios de microblogging.
- Servicios de bookmarking.
- etc.
Esto
hace que la calidad y popularidad de un medio en línea no sólo
dependa de sus contenidos sino de:
1.
La interacción que ofrece a sus usuarios: son importantes las
herramientas que el medio facilita para que sus usuarios interactúen
con los contenidos. Entre las más utilizadas actualmente por los
diarios en línea se encuentran
2.
El contexto en el que estos encuentran la información: con el fin de
ampliar la difusión de sus contenidos en la Web y facilitar el
acceso de los usuarios a los mismos, los diarios en línea han
trasladado su información a las redes sociales más populares. De
esta manera, la noticia se traslada desde un contexto puramente
periodístico, como los diarios en línea, a un contexto social donde
el medio actúa como un usuario más. La tabla dos muestra la
presencia y el alcance de diversos diarios en línea en algunas de
las principales redes sociales.
| My Space | |||
| El País | No | Sí | No |
| El Mundo | Sí (10 usuarios) |
Sí | No |
| Le Monde | Sí (21 usuarios) |
Sí | No |
| The Guardian | Sí (5.288 usuarios) |
No | No |
| The New York Times | Sí (362.245 usuarios) |
Sí | Sí (Canal de video) |
Diversos
medios en las principales redes sociales.
3.
Los formatos de comunicación utilizados: la Web 2.0 ha propiciado la
aparición de multitud de servicios especializados en el alojamiento
y la difusión de contenidos con un formato específico. Especial
éxito han alcanzado los servicios de alojamiento de video, como
Youtube , o de imágenes, como Flickr. La utilización de este tipo
de servicios ofrece a los medios nuevos canales de comunicación que
les acercan a sus potenciales usuarios, y les facilitan la creación
de auténticas comunidades. Un buen ejemplo sería el canal de video
creado en Youtube por el diario The New York Times, "The New
York Times Youtube Edition", en el que, en poco más de dos
años, se han realizado más de 365.000 reproducciones de sus videos.
| Youtube | Flickr | ||
| El País | No | No | Sí (3.500 usuarios) |
| El Mundo | No | No | No |
| Le Monde | No | No | Sí (3.500 usuarios) |
| The Guardian | No | Sí (280 usuarios) |
Sí (10.976 usuarios) |
| The New York Times | Sí (10.543 usuarios) |
No | Sí (340.283 usuarios) |
Presencia
de diversos medios en línea en diferentes servicios Web 2.0.
Sistema de recomendación
Los
sistemas
recomendadores
surgen como respuesta a la sobrecarga de información presente en
numerosos dominios, que dificulta a los usuarios identificar los
productos (artículos comerciales, contenidos de televisión, cursos
educativos, etc.) que son relevantes para ellos. Estas herramientas
ofrecen sugerencias personalizadas, seleccionando, de entre la gran
cantidad de opciones disponibles, aquellos productos que mejor
encajan con las preferencias de cada usuario. Para ello, las
diferentes estrategias de personalización que emplean estos sistemas
se basan en la información que recopilan en perfiles
personales.
La
creación y actualización de dichos perfiles son tareas clave en
cualquier sistema recomendador, ya que de ellos depende directamente
la calidad de las sugerencias ofrecidas. Sin embargo, la obtención
de información acerca de los intereses de los usuarios se ve
limitada a la que éstos proporcionan a través de su interacción
con el sistema, bien explícitamente (mediante valoraciones
cuantitativas o cualitativas de productos), bien implícitamente (por
ejemplo, en una plataforma web de comercio electrónico, sus
historiales de compra).
En
la Web 2.0 los
usuarios
han dejado de ser meros consumidores de información para convertirse
a su vez en productores
y difusores.
Millones de personas dedican un gran número de horas a diversos
medios
sociales
(blogs, redes sociales, foros especializados, etc.), interactuando y
compartiendo información en línea del mismo modo que lo hacen en el
mundo real. De ahí su gran potencial como fuente de conocimiento
para los sistemas recomendadores.
Uno
de los mayores
retos
perseguidos actualmente es el análisis
de la gran cantidad de datos
disponible en los medios sociales. Por un lado, las publicaciones de
los usuarios a menudo reflejan sus intereses, por lo que su procesado
permitirá incorporar nuevas preferencias a sus perfiles sin requerir
la interacción del usuario con el sistema. Por otra parte, de las
diversas conexiones establecidas entre los usuarios en los medios
sociales puede extraerse gran cantidad de información útil para
enriquecer el proceso de recomendación.
Gradiant
tiene
varias líneas de trabajo abiertas en el campo de la personalización
y está actualmente desarrollando un proyecto de inteligencia de
negocio que incluye la generación de perfiles a partir de medios
sociales
Red social

Una red social es una forma de representar una estructura social, asignándole un grafo, si dos elementos del conjunto de actores (tales como individuos u organizaciones) están relacionados de acuerdo a algún criterio (relación profesional, amistad, parentesco, etc.) entonces se construye una línea que conecta los nodos que representan a dichos elementos. El tipo de conexión representable en una red social es una relación diádica o lazo interpersonal, que se pueden interpretar como relaciones de amistad, parentesco, laborales, entre otros.
El análisis de redes sociales estudia esta estructura social aplicando la teoría de grafos e identificando las entidades como "nodos" o "vértices" y las relaciones como "enlaces" o "aristas". La estructura del grafo resultante es a menudo muy compleja. Como se ha dicho, En su forma más simple, una red social es un mapa de todos los lazos relevantes entre todos los nodos estudiados. Se habla en este caso de redes "socio céntricas" o "completas". Otra opción es identificar la red que envuelve a una persona (en los diferentes contextos sociales en los que interactúa); en este caso se habla de "red personal".
La red social también puede ser utilizada para medir el capital social (es decir, el valor que un individuo obtiene de los recursos accesibles a través de su red social). Estos conceptos se muestran, a menudo, en un diagrama donde los nodos son puntos y los lazos, líneas.
Red social también se suele referir a las plataformas en Internet. Las redes sociales de internet cuyo propósito es facilitar la comunicación y otros temas sociales en el sitio web.
Análisis de redes sociales
El
Análisis de redes sociales (relacionado con la teoría de redes)
ha emergido como una metodología clave en las modernas Ciencias
Sociales, entre las que se incluyen la sociología, la antropología,
la psicología social, la economía, la geografía, las Ciencias
políticas, la cienciometría, los estudios de comunicación,
estudios organizacionales y la sociolingüística. También ha ganado
un apoyo significativo en la física y la biología entre otras.
En
el lenguaje cotidiano se ha utilizado libremente la idea de "red
social" durante más de un siglo para denotar conjuntos
complejos de relaciones entre miembros de los sistemas sociales en
todas las dimensiones, desde el ámbito interpersonal hasta el
internacional. En 1954, el antropólogo de la Escuela de Mánchester
J. A. Barnes comenzó a utilizar sistemáticamente el término para
mostrar patrones de lazos, abarcando los conceptos tradicionalmente
utilizados por los científicos sociales: grupos delimitados (p.e.,
tribus, familias) y categorías sociales (p.e., género, etnia).
Académicos como S.D. Berkowitz, Stephen Borgatti, Ronald Burt,
Kathleen Carley, Martin Everett, Katherine Faust, Linton Freeman,
Mark Granovetter, David Knoke, David Krackhardt, Peter Marsden,
Nicholas Mullins, Anatol Rapoport, Stanley Wasserman, Barry Wellman,
Douglas R. White y Harrison White expandieron el uso del análisis de
redes sociales sistemático.
El
análisis de redes sociales ha pasado de ser una metáfora sugerente
para constituirse en un enfoque analítico y un paradigma, con sus
principios teóricos, métodos de software para análisis de redes
sociales y líneas de investigación propios. Los analistas estudian
la influencia del todo en las partes y viceversa, el efecto producido
por la acción selectiva de los individuos en la red; desde la
estructura hasta la relación y el individuo, desde el comportamiento
hasta la actitud. Como se ha dicho estos análisis se realizan bien
en redes completas, donde los lazos son las relaciones específicas
en una población definida, o bien en redes personales (también
conocidas como redes egocéntricas, aunque no son exactamente
equiparables), donde se estudian "comunidades personales".2
La distinción entre redes totales/completas y redes
personales/egocéntricas depende mucho más de la capacidad del
analista para recopilar los datos y la información. Es decir, para
grupos tales como empresas, escuelas o sociedades con membretar, el
analista espera tener información completa sobre quien está en la
red, siendo todos los participantes egos y alteri potenciales. Los
estudios personales/egocéntricos son conducidos generalmente cuando
las identidades o egos se conocen, pero no sus alteri. Estos estudios
permiten a los egos aportar información sobre la identidad de sus
alteri y no hay la expectativa de que los distintos egos o conjuntos
de alteri estén vinculados con cada uno de los otros.
Una red
construida a partir de una bola de nieve se refiere a la idea de que
los alteri son identificados en una encuesta por un conjunto de Egos
iniciales (oleada cero) y estos mismos alteri se convierten en egos
en la oleada 1 y nombran a otros alteri adicionales y así
sucesivamente hasta que el porcentaje de alteri nuevos empieza a
disminuir. Aunque hay varios límites logísticos en la conducción
de estudios de bola de nieve, hay desarrollo recientes para examinar
redes híbridas, según el cual egos en redes completas pueden
nombrar a alteri que de otro modo no estarían identificados,
posibilitando que éstos sean visibles para todos los egos de la
red.3 La red híbrida, puede ser valiosa para examinar redes
totales/completas sobre las que hay la expectativa de incluir actores
importantes más allá de los identificados formalmente. Por ejemplo,
los empleados de una compañía a menudo trabajan con consultores
externos que son parte de una red que no pueden definir totalmente
antes de la recolección de datos.
Historia del análisis de redes sociales
Linton
Freeman ha escrito la historia del progreso de las redes sociales y
del análisis de redes sociales.
Los
precursores de las redes sociales, a finales del siglo XIX incluyen a
Émile Durkheim y a Ferdinand Tönnies. Tönnies argumentó que los
grupos sociales pueden existir bien como lazos sociales personales y
directos que vinculan a los individuos con aquellos con quienes
comparte valores y creencias (gemeinschaft), o bien como
vínculos sociales formales e instrumentales (gesellschaft).
Durkheim aportó una explicación no individualista al hecho social,
argumentando que los fenómenos sociales surgen cuando los individuos
que interactúan constituyen una realidad que ya no puede explicarse
en términos de los atributos de los actores individuales. Hizo
distinción entre una sociedad tradicional -con "solidaridad
mecánica"- que prevalece si se minimizan las diferencias
individuales; y una sociedad moderna -con "solidaridad
orgánica"- que desarrolla cooperación entre individuos
diferenciados con roles independientes.
Por
su parte, Georg Simmel a comienzos del siglo XX, fue el primer
estudioso que pensó directamente en términos de red social. Sus
ensayos apuntan a la naturaleza del tamaño de la red sobre la
interacción y a la probabilidad de interacción en redes
ramificadas, de punto flojo, en lugar de en grupos.
Después
de una pausa en las primeras décadas del siglo XX, surgieron tres
tradiciones principales en las redes sociales. En la década de 1930,
Jacob L. Moreno fue pionero en el registro sistemático y en el
análisis de la interacción social de pequeños grupos, en especial
las aulas y grupos de trabajo (sociometría), mientras que un grupo
de Harvard liderado por W. Lloyd Warner y Elton Mayo exploró las
relaciones interpersonales en el trabajo. En 1940, en su discurso a
los antropólogos británicos, A.R. Radcliffe-Brown instó al estudio
sistemático de las redes.8 Sin embargo, tomó unos 15 años antes de
esta convocatoria fuera seguida de forma sistemática.
El
Análisis de redes sociales se desarrolló con los estudios de
parentesco de Elizabeth Bott en Inglaterra entre los años 1950, y
con los estudios de urbanización del grupo de antropólogos de la
Universidad de Mánchester (acompañando a Max Gluckman y después a
J. Clyde Mitchell) entre los años 1950 y 1960, investigando redes
comunitarias en el sur de África, India y el Reino Unido. Al mismo
tiempo, el antropólogo británico Nadel SF Nadel codificó una
teoría de la estructura social que influyó posteriormente en el
análisis de redes.
Entre
los años 1960 y 1970, un número creciente de académicos trabajaron
en la combinación de diferentes temas y tradiciones. Un grupo fue el
de Harrison White y sus estudiantes en el Departamento de Relaciones
Sociales de la Universidad de Harvard: Ivan Chase, Bonnie Erickson,
Harriet Friedmann, Mark Granovetter, Nancy Howell, Joel Levine,
Nicholas Mullins, John Padgett, Michael Schwartz y Barry Wellman.
Otras personas importantes en este grupo inicial fueron Charles
Tilly, quien se enfocó en redes en sociología política y
movimientos sociales, y Stanley Milgram, quien desarrolló la tesis
de los "seis grados de separación".10 Mark Granovetter y
Barry Wellman están entre los antiguos estudiantes de White que han
elaborado y popularizado el análisis de redes sociales.
Pero
el grupo de White no fue el único. En otros lugares, distintos
académicos desarrollaron un trabajo independiente significativo:
científicos sociales interesados en aplicaciones matemáticas de la
Universidad de California Irvine en torno a Linton Freeman,
incluyendo a John Boyd, Susan Freeman, Kathryn Faust, A. Kimball
Romney y Douglas White; analistas cuantitativos de la Universidad de
Chicago, incluyendo a Joseph Galaskiewicz, Wendy Griswold, Edward
Laumann, Peter Marsden, Martina Morris, y John Padgett; y académicos
de la comunicación en la Universidad de Michigan, incluyendo a Nan
Lin y Everett Rogers. En la década de 1970, se constituyó un grupo
de sociología sustantiva orientada de la Universidad de Toronto, en
torno a antiguos estudiantes de Harrison White: S.D. Berkowitz,
Harriet Friedmann, Nancy Leslie Howard, Nancy Howell, Lorne Tepperman
y Barry Wellman, y también los acompañó el señalado modelista y
teorético de los juegos Anatol Rapoport. En términos de la teoría,
criticó el individualismo metodológico y los análisis basados en
grupos, argumentando que ver el mundo desde la óptica de las redes
sociales ofrece un apalancamiento más analítico.12
Investigación sobre redes sociales
El
análisis de redes sociales se ha utilizado en epidemiología para
ayudar a entender cómo los patrones de contacto humano favorecen o
impiden la propagación de enfermedades como el VIH en una población.
La evolución de las redes sociales a veces puede ser simulada por el
uso de modelos basados en agentes, proporcionando información sobre
la interacción entre las normas de comunicación, propagación de
rumores y la estructura social.
El
análisis de redes sociales también puede ser una herramienta eficaz
para la vigilancia masiva - por ejemplo, el Total Information
Awareness realizó una investigación a fondo sobre las estrategias
para analizar las redes sociales para determinar si los ciudadanos de
EE.UU. eran o no amenazas políticas.
La
teoría de difusión de innovaciones explora las redes sociales y su
rol en la influencia de la difusión de nuevas ideas y prácticas. El
cambio en los agentes y en la opinión del líder a menudo tienen un
papel más importante en el estímulo a la adopción de innovaciones,
a pesar de que también intervienen factores inherentes a las
innovaciones.
Por
su parte, Robin Dunbar sugirió que la medída típica en una red
egocéntrica está limitado a unos 150 miembros, debido a los
posibles límites de la capacidad del canal de la comunicación
humana. Esta norma surge de los estudios transculturales de la
sociología y especialmente de la antropología sobre la medida
máxima de una aldea (en el lenguaje moderno mejor entendido como una
ecoaldea). Esto está teorizado en la psicología evolutiva, cuando
afirma que el número puede ser una suerte de límite o promedio de
la habilidad humana para reconocer miembros y seguir hechos
emocionales con todos los miembros de un grupo. Sin embargo, este
puede deberse a la intervención de la economía y la necesidad de
seguir a los «polizones», lo que hace que sea más fácil en
grandes grupos sacar ventaja de los beneficios de vivir en una
comunidad sin contribuir con esos beneficios.
Mark
Granovetter encontró en un estudio que un número grande de lazos
débiles puede ser importante para la búsqueda de información y la
innovación. Los cliques tienen una tendencia a tener opiniones más
homogéneas, así como a compartir muchos rasgos comunes. Esta
tendencia homofílica es la razón por la cual los miembros de las
camarillas se atraen en primer término. Sin embargo, de forma
parecida, cada miembro del clique también sabe más o menos lo que
saben los demás. Para encontrar nueva información o ideas, los
miembros del clique tendrán que mirar más allá de este a sus otros
amigos y conocidos. Esto es lo que Granovetter llamó «la fuerza de
los lazos débiles».
Hay
otras aplicaciones del término red social. Por ejemplo, el Guanxi es
un concepto central en la sociedad china (y otras culturas de Asia
oriental), que puede resumirse como el uso de la influencia personal.
El Guanxi puede ser estudiado desde un enfoque de red social.
El
fenómeno del mundo pequeño es la hipótesis sobre que la cadena de
conocidos sociales necesaria para conectar a una persona arbitraria
con otra persona arbitraria en cualquier parte del mundo, es
generalmente corta. El concepto dio lugar a la famosa frase de seis
grados de separación a partir de los resultados del «experimento de
un mundo pequeño» hecho en 1967 por el psicólogo Stanley Milgram.
En el experimento de Milgram, a una muestra de individuos EE.UU. se
le pidió que hiciera llegar un mensaje a una persona objetivo en
particular, pasándolo a lo largo de una cadena de conocidos. La
duración media de las cadenas exitosas resultó ser de unos cinco
intermediarios, o seis pasos de separación (la mayoría de las
cadenas en este estudio ya no están completas). Los métodos (y la
ética también) del experimento de Milgram fueron cuestionados más
tarde por un estudioso norteamericano, y algunas otras
investigaciones para replicar los hallazgos de Milgram habrían
encontrado que los grados de conexión necesarios podrían ser
mayores.14 Investigadores académicos continúan exploranto este
fenómeno dado que la tecnología de comunicación basada en Internet
ha completado la del teléfono y los sistemas postales disponibles en
los tiempos de Milgram. Un reciente experimento electrónico del
mundo pequeño en la Universidad de Columbia, arrojó que cerca de
cinco a siete grados de separación son suficientes para conectar
cualesquiera dos personas a través de e-mail.
Los
grafos de colaboración pueden ser utilizados para ilustrar buenas y
malas relaciones entre los seres humanos. Un vínculo positivo entre
dos nodos denota una relación positiva (amistad, alianza, citas) y
un vínculo negativo entre dos nodos denota una relación negativa
(odio, ira). Estos gráficos de redes sociales pueden ser utilizados
para predecir la evolución futura de la gráfica. En ellos, existe
el concepto de ciclos «equilibrados» y «desequilibrados». Un
ciclo de equilibrio se define como aquél donde el producto de todos
los signos son positivos. Los gráficos balanceados representan un
grupo de personas con muy poca probabilidad de cambio en sus
opiniones sobre las otras personas en el grupo. Los gráficos
desequilibrados representan un grupo de individuo que es muy probable
que cambie sus opiniones sobre los otros en su grupo. Por ejemplo, en
un grupo de 3 personas (A, B y C) donde A y B tienen una relación
positiva, B y C tienen una relación positiva, pero C y A tienen una
relación negativa, es un ciclo de desequilibrio. Este grupo es muy
probable que se transforme en un ciclo equilibrado, tal que la B sólo
tiene una buena relación con A, y tanto A como B tienen una relación
negativa con C. Al utilizar el concepto de ciclos balanceados y
desbalanceados, puede predecirse la evolución de la evolución de un
grafo de red social.
Un
estudio ha descubierto que la felicidad tiende a correlacionarse en
redes sociales. Cuando una persona es feliz, los amigos cercanos
tienen una probabilidad un 25 por ciento mayor de ser también
felices. Además, las personas en el centro de una red social tienden
a ser más feliz en el futuro que aquellos situados en la periferia.
En las redes estudiadas se observaron tanto a grupos de personas
felices como a grupos de personas infelices, con un alcance de tres
grados de separación: se asoció felicidad de una persona con el
nivel de felicidad de los amigos de los amigos de sus amigos.16
Algunos
investigadores han sugerido que las redes sociales humanas pueden
tener una base genética.17 Utilizando una muestra de mellizos del
National Longitudinal Study of Adolescent Health, han encontrado que
el in-degree (número de veces que una persona es nombrada como amigo
o amiga), la transitividad (la probabilidad de que dos amigos sean
amigos de un tercero), y la intermediación y centralidad (el número
de lazos en la red que pasan a través de una persona dada) son
significativamente hereditarios. Los modelos existentes de formación
de redes no pueden dar cuenta de esta variación intrínseca, por lo
que los investigadores proponen un modelo alternativo «Atraer y
Presentar», que pueda explicar ese caracter hereditario y muchas
otras características de las redes sociales humanas.18
Métricas o medidas en el análisis de redes sociales
- Conector
- Un lazo puede ser llamado conector si su eliminación causa que los puntos que conecta se transformen en componentes distintos de un grafo.
- Centralidad
- Medidas de la importancia de un nodo dentro de una red, dependiendo de la ubicación dentro de ésta. Ejemplos de medidas de centralidad son la centralidad de grado, la cercanía, la intermediación y la centralidad de vector propio.
- Centralización
- La diferencia entre el número de enlaces para cada nodo, dividido entre la cantidad máxima posible de diferencias. Una red centralizada tendrá muchos de sus vínculos dispersos alrededor de uno o unos cuantos puntos nodales, mientras que una red descentralizada es aquella en la que hay poca variación entre el número de enlaces de cada nodo posee.
- Coeficiente de agrupamiento
- Una medida de la probabilidad de que dos personas vinculadas a un nodo se asocien a sí mismos. Un coeficiente de agrupación más alto indica un mayor «exclusivismo».
-
- Cohesión
- El grado en que los actores se conectan directamente entre sí por vínculos cohesivos. Los grupos se identifican como ‘cliques’ si cada individuo está vinculado directamente con con cada uno de los otros, ‘círculos sociales’ si hay menos rigor en el contacto directo y este es inmpreciso, o bloques de cohesión estructural si se requiere la precisión.19
- (Nivel individual) Densidad
- El grado de relaciones de un demandado de conocerse unos a otros / proporción de lazos entre las mencione de un individuo. La densidad de la red, o densidad global, es la proporción de vínculos en una red en relación con el total de vínculos posibles (redes escasas versus densas)
- Flujo de centralidad de intermediación
- El grado en que un nodo contribuye a la suma del flujo máximo entre todos los pares de noso (excluyendo ese nodo).
Redes sociales en Internet
El
software germinal de las redes sociales parte de la teoría de los
seis grados de separación, según la cual toda la gente del planeta
está conectada a través de no más de seis personas. De hecho,
existe una patente en EEUU conocida como six degrees patent
por la que ya han pagado Tribe y LinkedIn. Hay otras muchas patentes
que protegen la tecnología para automatizar la creación de redes y
las aplicaciones relacionadas con éstas.
 Estas
redes sociales se basan en la teoría de los seis grados, Seis grados
de separación es la teoría de que cualquiera en la Tierra puede
estar conectado a cualquier otra persona en el planeta a través de
una cadena de conocidos que no tiene más de seis intermediarios. La
teoría fue inicialmente propuesta en 1929 por el escritor húngaro
Frigyes Karinthy en una corta historia llamada Chains. El concepto
está basado en la idea que el número de conocidos crece
exponencialmente con el número de enlaces en la cadena, y sólo un
pequeño número de enlaces son necesarios para que el conjunto de
conocidos se convierta en la población humana entera.
Estas
redes sociales se basan en la teoría de los seis grados, Seis grados
de separación es la teoría de que cualquiera en la Tierra puede
estar conectado a cualquier otra persona en el planeta a través de
una cadena de conocidos que no tiene más de seis intermediarios. La
teoría fue inicialmente propuesta en 1929 por el escritor húngaro
Frigyes Karinthy en una corta historia llamada Chains. El concepto
está basado en la idea que el número de conocidos crece
exponencialmente con el número de enlaces en la cadena, y sólo un
pequeño número de enlaces son necesarios para que el conjunto de
conocidos se convierta en la población humana entera.
El
término red social es acuñado principalmente a los antropólogos
ingleses John Barnes y Elizabeth Bott, ya que, para ellos resultaba
imprescindible cosiderar lazos externos a los famliares,
residenciales o de pertenencia a algún grupo social.
Los
fines que han motivado la creación de las llamadas redes sociales
son varios, principalmente, es el diseñar un lugar de interacción
virtual, en el que millones de personas alrededor del mundo se
concentran con diversos intereses en común.
Recogida
también en el libro "Six Degrees: The Science of a Connected
Age” del sociólogo Duncan Watts, y que asegura que es posible
acceder a cualquier persona del planeta en tan solo seis “saltos”.
Según
esta Teoría, cada persona conoce de media, entre amigos, familiares
y compañeros de trabajo o escuela, a unas 100 personas. Si cada uno
de esos amigos o conocidos cercanos se relaciona con otras 100
personas, cualquier individuo puede pasar un recado a 10.000 personas
más tan solo pidiendo a un amigo que pase el mensaje a sus amigos.
Estos
10.000 individuos serían contactos de segundo nivel, que un
individuo no conoce pero que puede conocer fácilmente pidiendo a sus
amigos y familiares que se los presenten, y a los que se suele
recurrir para ocupar un puesto de trabajo o realizar una compra.
Cuando preguntamos a alguien, por ejemplo, si conoce una secretaria
interesada en trabajar estamos tirando de estas redes sociales
informales que hacen funcionar nuestra sociedad. Este argumento
supone que los 100 amigos de cada persona no son amigos comunes. En
la práctica, esto significa que el número de contactos de segundo
nivel será sustancialmente menor a 10.000 debido a que es muy usual
tener amigos comunes en las redes sociales.
Si
esos 10.000 conocen a otros 100, la red ya se ampliaría a 1.000.000
de personas conectadas en un tercer nivel, a 100.000.000 en un cuarto
nivel, a 10.000.000.000 en un quinto nivel y a 1.000.000.000.000 en
un sexto nivel. En seis pasos, y con las tecnologías disponibles, se
podría enviar un mensaje a cualquier lugar individuo del planeta.
Evidentemente
cuanto más pasos haya que dar, más lejana será la conexión entre
dos individuos y más difícil la comunicación. Internet, sin
embargo, ha eliminado algunas de esas barreras creando verdaderas
redes sociales mundiales, especialmente en segmento concreto de
profesionales, artistas, etc.
En
la década de los 50, Ithiel de Sola Pool (MIT) y Manfred Kochen
(IBM) se propusieron demostrar la teoría matemáticamente. Aunque
eran capaces de enunciar la cuestión "dado un conjunto de N
personas, ¿cual es la probabilidad de que cada miembro de estos N
estén conectados con otro miembro vía k1, k2, k3,..., kn enlaces?",
después de veinte años todavía eran incapaces de resolver el
problema a su propia satisfacción.
En
1967, el psicólogo estadounidense Stanley Milgram ideó una nueva
manera de probar la Teoría, que él llamó "el problema del
pequeño mundo". El experimento del mundo pequeño de Milgram
consistió en la selección al azar de varias personas del medio
oeste estadounidense para que enviaran tarjetas postales a un extraño
situado en Massachusetts, situado a varios miles de millas de
distancia. Los remitentes conocían el nombre del destinatario, su
ocupación y la localización aproximada. Se les indicó que enviaran
el paquete a una persona que ellos conocieran directamente y que
pensaran que fuera la que más probabilidades tendría, de todos sus
amigos, de conocer directamente al destinatario. Esta persona tendría
que hacer lo mismo y así sucesivamente hasta que el paquete fuera
entregado personalmente a su destinatario final.
Aunque
los participantes esperaban que la cadena incluyera al menos cientos
de intermediarios, la entrega de cada paquete solamente llevó, como
promedio, entre cinco y siete intermediarios. Los descubrimientos de
Milgram fueron publicados en "Psychology Today" e
inspiraron la frase seis grados de separación.
En
The social software weblog han agrupado 120 sitios web en 10
categorías y QuickBase también ha elaborado un completo cuadro
sobre redes sociales en Internet.
El
origen de las redes sociales se remonta, al menos, a 1995, cuando
Randy Conrads crea el sitio web classmates.com. Con esta red social
se pretende que la gente pueda recuperar o mantener el contacto con
antiguos compañeros del colegio, instituto, universidad, etcétera.
En
2002 comienzan a aparecer sitios web promocionando las redes de
círculos de amigos en línea cuando el término se empleaba para
describir las relaciones en las comunidades virtuales, y se hizo
popular en 2003 con la llegada de sitios tales como MySpace o Xing.
Hay más de 200 sitios de redes sociales, aunque Friendster ha sido
uno de los que mejor ha sabido emplear la técnica del círculo de
amigos.[cita requerida]
La popularidad de estos sitios creció rápidamente y grandes
compañías han entrado en el espacio de las redes sociales en
Internet. Por ejemplo, Google lanzó Orkut el 22 de enero de 2004.
Otros buscadores como KaZaZZ! y Yahoo crearon redes sociales en 2005.
En
estas comunidades, un número inicial de participantes envían
mensajes a miembros de su propia red social invitándoles a unirse al
sitio. Los nuevos participantes repiten el proceso, creciendo el
número total de miembros y los enlaces de la red. Los sitios ofrecen
características como actualización automática de la libreta de
direcciones, perfiles visibles, la capacidad de crear nuevos enlaces
mediante servicios de presentación y otras maneras de
conexión social en línea. Las redes sociales también pueden
crearse en torno a las relaciones comerciales.
Las
herramientas informáticas para potenciar la eficacia de las redes
sociales online («software social»), operan en tres ámbitos, «las
3 Cs», de forma cruzada:
- Comunicación (nos ayudan a poner en común conocimientos).
- Comunidad (nos ayudan a encontrar e integrar comunidades).
- Cooperación (nos ayudan a hacer cosas juntos).
El
establecimiento combinado de contactos (blended networking) es
una aproximación a la red social que combina elementos en línea y
del mundo real para crear una mezcla. Una red social de personas es
combinada si se establece mediante eventos cara a cara y una
comunidad en línea. Los dos elementos de la mezcla se complementan
el uno al otro. Vea también computación social.
Las
redes sociales continúan avanzando en Internet a pasos agigantados,
especialmente dentro de lo que se ha denominado Web 2.0 y Web 3.0, y
dentro de ellas, cabe destacar un nuevo fenómeno que pretende ayudar
al usuario en sus compras en Internet: las redes sociales de
compras. Las redes sociales de compras tratan de convertirse en
un lugar de consulta y compra. Un espacio en el que los usuarios
pueden consultar todas las dudas que tienen sobre los productos en
los que están interesados, leer opiniones y escribirlas, votar a sus
productos favoritos, conocer gente con sus mismas aficiones y, por
supuesto, comprar ese producto en las tiendas más importantes con un
solo clic. Esta tendencia tiene nombre, se llama Shopping 2.0.
Tipología de redes sociales en Internet
No
hay unanimidad entre los autores a la hora de proponer una tipología
concreta. En algunos sitios se aplica la misma tipología que en su
día se utilizó para los portales, dividirlos en horizontales y
verticales:
- Horizontales: buscan proveer herramientas para la interrelación en general: Facebook, Google+, Hi5 o Bebo.
- Verticales; pueden clasificarse:
- Por tipo de usuario; dirigidos a un público específico. Profesionales (Linkedin), Amantes de los Gatos (MyCatSpace), etcétera.
- Por tipo de actividad; los que promueven una actividad particular. Videos YouTube, Microbloggin Twitter, etcétera.
Wikis
 Un
(o una) wiki
(del hawaiano wiki,
'rápido') es un sitio web cuyas páginas pueden ser editadas por
múltiples voluntarios a través del navegador web. Los usuarios
pueden crear, modificar o borrar un mismo texto que comparten. Los
textos o «páginas wiki» tienen títulos únicos. Si se escribe el
título de una «página wiki» en algún sitio del wiki entre dobles
corchetes ([[...]]), esta palabra se convierte en un «enlace web» a
la página correspondiente.
Un
(o una) wiki
(del hawaiano wiki,
'rápido') es un sitio web cuyas páginas pueden ser editadas por
múltiples voluntarios a través del navegador web. Los usuarios
pueden crear, modificar o borrar un mismo texto que comparten. Los
textos o «páginas wiki» tienen títulos únicos. Si se escribe el
título de una «página wiki» en algún sitio del wiki entre dobles
corchetes ([[...]]), esta palabra se convierte en un «enlace web» a
la página correspondiente. |
| Wikipedia: Uno de los más famosos wikis |
La aplicación
de mayor peso y a la que le debe su mayor fama hasta el momento ha
sido la creación de enciclopedias colectivas, género al que
pertenece la Wikipedia. Existen muchas otras aplicaciones más
cercanas a la coordinación de informaciones y acciones, o la puesta
en común de conocimientos o textos dentro de grupos.
La
mayor parte de los wikis actuales conservan un historial de cambios
que permite recuperar fácilmente cualquier estado anterior y ver qué
usuario hizo cada cambio, lo cual facilita enormemente el
mantenimiento conjunto y el control de usuarios nocivos.
Habitualmente, sin necesidad de una revisión previa, se actualiza el
contenido que muestra la página wiki editada.
Historia
El
origen de los wikis está en la comunidad de patrones de diseño,
cuyos integrantes los utilizaron para escribir patrones de
programación. El primer WikiWikiWeb fue creado por Ward
Cunningham, quien inventó y dio nombre al concepto wiki, y
produjo la primera implementación de un servidor WikiWiki para el
repositorio de patrones del Portland (Portland Pattern Repository) en
1995. En palabras del propio Cunningham, un wiki es «la base de
datos en línea más simple que pueda funcionar» (the simplest
online database that could possibly work). El wiki de Ward
aún es uno de los sitios web wiki más populares.
En
enero de 2001, los fundadores del proyecto de enciclopedia Nupedia,
Jimmy Wales y Larry Sanger, decidieron utilizar un wiki como base
para el proyecto de enciclopedia Wikipedia. Originalmente se usó el
software UseMod, pero luego crearon un software propio, MediaWiki,
que ha sido adoptado después por muchos otros wikis.
El
wiki más grande que existe es la versión en inglés de Wikipedia,
seguida por varias otras versiones del proyecto. Los wikis ajenos a
Wikipedia son mucho más pequeños y con menor participación de
usuarios, generalmente debido al hecho de ser mucho más
especializados. Es muy frecuente, por ejemplo, la creación de wikis
para proveer de documentación a programas informáticos,
especialmente los desarrollados en software libre.
Ventajas
La
principal utilidad de un wiki es que permite crear y mejorar las
páginas de forma inmediata, dando una gran libertad al usuario, y
por medio de una interfaz muy simple. Esto hace que más gente
participe en su modificación, a diferencia de los sistemas
tradicionales, donde resulta más difícil que los usuarios del sitio
contribuyan a mejorarlo.
Dada
la gran rapidez con la que se actualizan los contenidos, la palabra
«wiki» adopta todo su sentido. El «documento» de hipertexto
resultante, denominado también «wiki» o «WikiWikiWeb», lo
produce típicamente una comunidad de usuarios. Muchos de estos
lugares son inmediatamente identificables por su particular uso de
palabras en mayúsculas, o texto capitalizado - uso que
consiste en poner en mayúsculas las iniciales de las palabras de una
frase y eliminar los espacios entre ellas - como por ejemplo en
EsteEsUnEjemplo. Esto convierte automáticamente a la frase en
un enlace. Este wiki, en sus orígenes, se comportaba de esa
manera, pero actualmente se respetan los espacios y sólo hace falta
encerrar el título del enlace entre dos corchetes.
Inconvenientes
El
más importante se describe como la posibilidad de introducir adendos
y modificaciones carentes de autenticidad y rigor. Cualquier persona
podrá intervenir sin que su información o comentarios estén
suficientemente contrastados. Debido a ello, se toman las medidas más
adecuadas al alcance de los mecanismos editoriales con objeto de
optimizar la fiabilidad de las informaciones introducidas.
Características
Según
su creador una wiki es “la base de datos en línea más simple que
pueda funcionar". Se trata de un tipo de página web que brinda
la posibilidad de que multitud de usuarios puedan editar sus
contenidos a través del navegador web, con ciertas restricciones
mínimas. De esta forma permite que múltiples autores puedan crear,
modificar o eliminar los contenidos. Se puede identificar a cada
usuario que realiza un cambio y recuperar los contenidos modificados,
volviendo a un estado anterior. Estas características facilitan el
trabajo en colaboración así como la coordinación de acciones e
intercambio de información sin necesidad de estar presentes
físicamente ni conectados de forma simultánea. El ejemplo más
conocido y de mayor tamaño de este tipo de páginas web es la
enciclopedia colaborativa Wikipedia (www.wikipedia.com). A favor: Es
una fuente de información y bibliográfica de construcción
colectiva. Problemas: La información publicada puede provenir de
fuentes erróneas o no válidas. Solución/recomendaciones: Es
recomendable trabajar criterios sobre el empleo de fuentes de
información confiables y formas de validar los contenidos.
Un
wiki permite que se escriban artículos colectivamente (co-autoría)
por medio de un lenguaje de wikitexto editado mediante un navegador.
Una página wiki singular es llamada «página wiki», mientras que
el conjunto de páginas (normalmente interconectadas mediante
hipervínculos) es «el wiki». Es mucho más sencillo y fácil de
usar que una base de datos.
Una
característica que define la tecnología wiki es la facilidad con
que las páginas pueden ser creadas y actualizadas. En general no
hace falta revisión para que los cambios sean aceptados. La mayoría
de wikis están abiertos al público sin la necesidad de registrar
una cuenta de usuario. A veces se requiere hacer login para obtener
una cookie de «wiki-firma», para autofirmar las ediciones propias.
Otros wikis más privados requieren autenticación de usuario.
Perspectivas pedagógicas de Wiki
Por
lo explicado, las Wiki son una muy buena opción pedagógica para
realizar actividades educativas, ya que como explica Mariana Maggio,
se pueden generar propuestas que los alumnos puedan integrar en las
Wiki a partir de la reconstrucción de las mismas en un sentido
didáctico. En la actualidad los documentos Web, como lo es el
ejemplo de las Wiki, crean tendencias y cuando éstas configuran los
usos de los niños y los jóvenes, es importante que los educadores
las reconozcan y se preocupen por entenderlas a partir de su
exploración.
Para
Maggio,“un proyecto didáctico maravilloso puede ser, cuando el
tema lo justifique, generar contenidos para Wikipedia o revisar los
publicados allí: entender el tema de un modo profundo, verificar los
contenidos, transparentar y discutir los criterios, ampliar lo
publicado, ofrecer versiones y especificaciones de alto valor local”
Un
wiki también puede ser un espacio usado para seguimiento individual
de los alumnos, donde ellos puedan crear sus proyectos
independientemente y el profesor pueda intervenir guiando y
corrigiendo. Permite la creación colectiva de documentos en un
lenguaje simple de marcas utilizando un navegador web. Generalmente
no se hacen revisiones previas antes de aceptar las modificaciones y
la mayoría de los wikis están abiertas. Permite a los participantes
trabajar juntos en páginas web, para añadir o modificar su
contenido. Las versiones antiguas nunca se eliminan y pueden
restaurarse. Se puede seleccionar diferentes tipos de wiki; profesor,
grupo, alumno.
Páginas y edición
En
un wiki tradicional existen tres representaciones por cada página:
- El «código fuente», que pueden editar los usuarios. Es el formato almacenado localmente en el servidor. Normalmente es texto plano, sólo es visible para el usuario cuando lo muestra la operación «Editar».
- Una plantilla (en ocasiones generada internamente) que define la disposición y elementos comunes de todas las páginas.
- El código HTML, puesto en tiempo real por el servidor a partir del código fuente cada vez que la página se solicita.
El
código fuente es potenciado mediante un lenguaje de marcado
simplificado para hacer varias convenciones visuales y estructurales.
Por ejemplo, el uso del asterisco «*» al empezar una línea de
texto significa que se generará una lista desordenada de elementos
(bullet-list). El estilo y la sintaxis pueden variar en
función de la implementación, alguna de las cuales también permite
etiquetas HTML.
¿Por qué no HTML?
La
razón de este diseño es que el HTML, con muchas de sus etiquetas
crípticas, es difícil de leer para usuarios no habituados a la
tecnología. Hacer visibles las etiquetas de HTML provoca que el
texto en sí sea difícil de leer y editar para la mayoría de
usuarios. Por lo tanto, se promueve el uso de edición en texto llano
con convenciones para la estructura y el estilo fáciles de
comprender.
A
veces es deseable que los usuarios no puedan usar ciertas
funcionalidades que el HTML permite, tales como JavaScript, CSS y
XML. Se consigue consistencia en la visualización, así como
seguridad adicional para el usuario. En muchas inserciones de wiki,
un hipervínculo es exactamente tal como se muestra, al contrario de
lo que ocurre en el HTML.
Estándar
Durante
años el estándar de facto fue la sintaxis del WikiWikiWeb original.
Actualmente las instrucciones de formateo son diferentes dependiendo
del motor del wiki. Los wikis simples permiten sólo formateo de
texto básico, mientras que otros más complejos tienen soporte para
cuadros, imágenes, fórmulas e incluso otros elementos más
interactivos tales como encuestas y juegos. Debido a la dificultad de
usar varias sintaxis, se están haciendo esfuerzos para definir un
estándar de marcado (ver esfuerzos de Meatball y Tikiwiki).
Vincular y crear páginas
Los
wikis son un auténtico medio de hipertexto, con estructuras de
navegación no lineal. Cada página contiene un gran número de
vínculos a otras páginas. En grandes wikis existen las páginas de
navegación jerárquica, normalmente como consecuencia del proceso de
creación original, pero no es necesario usarlas. Los vínculos se
usan con una sintaxis específica, el «patrón de vínculos».
CamelCase
Originalmente
gran parte de wikis usaban CamelCase como patrón de vínculos,
poniendo frases sin espacios y poniendo la primera letra de cada
palabra en mayúscula (por ejemplo, la palabra «CamelCase»). Este
método es muy fácil, pero hace que los links se escriban de una
manera que se desvía de la escritura estándar. Los wikis basados en
CamelCase se distinguen instantáneamente por los links con nombres
como: «TablaDeContenidos», «PreguntasFrecuentes». Por
consiguiente, comenzaron a desarrollarse otras soluciones.
Vínculos libres
Los
«vínculos libres», usados por primera vez por CLiki, usan un
formato tipo _(vínculo). Por ejemplo, _(Tabla de contenidos),
_(Preguntas frecuentes). Otros motores de wiki usan distintos signos
de puntuación.
Interwiki
Interwiki
permite vínculos entre distintas comunidades wiki.
Las
nuevas páginas se crean simplemente creando un vínculo apropiado.
Si el vínculo no existe, se acostumbra a destacar como «vínculo
roto». Siguiendo el vínculo se abre una página de edición, que
permite al usuario introducir el texto para la nueva página wiki.
Este mecanismo asegura que casi no se generen páginas huérfanas (es
decir, páginas que no tienen ningún vínculo apuntando a ellas).
Además se mantiene un nivel alto de conectividad.
Búsqueda
La
mayoría de wikis permite al menos una búsqueda por títulos, a
veces incluso una búsqueda por texto completo. La escalabilidad de
la búsqueda depende totalmente del hecho de que el motor del wiki
disponga de una base de datos o no: es necesario el acceso a una base
de datos indexada para hacer búsquedas rápidas en wikis grandes. En
Wikipedia el botón «Ir» permite a los lectores ir directamente a
una página que concuerde con los criterios de búsqueda. El motor de
MetaWiki se creó para habilitar búsquedas en múltiples wikis.
Control de cambios
Los
wikis suelen diseñarse con la filosofía de aumentar la facilidad de
corrección de los errores, y no la de reducir la dificultad de
cometerlos. Los wikis son muy abiertos, pero incluso así
proporcionan maneras de verificar la validez de los últimos cambios
al contenido de las páginas. En casi todos los wikis hay una página
específica, «Cambios recientes», que enumera las ediciones más
recientes de artículos, o una lista con los cambios hechos durante
un período. Algunos wikis pueden filtrar la lista para deshacer
cambios hechos por vandalismo.
Desde
el registro de cambios suele haber otras funciones: el «Historial de
revisión» muestra versiones anteriores de la página, y la
característica «diff» destaca los cambios entre dos revisiones.
Usando el historial, un editor puede ver y restaurar una versión
anterior del artículo, y la característica «diff» se puede usar
para decidir cuándo eso es necesario. Un usuario normal del wiki
puede ver el «diff» de una edición listada en «Cambios recientes»
y, si es una edición inaceptable, consultar el historial y restaurar
una versión anterior. Este proceso es más o menos complicado, según
el software que use el wiki.
En
caso de que las ediciones inaceptables se pasen por alto en «Cambios
recientes», algunos motores de wiki proporcionan control de
contenido adicional. Se pueden monitorizar para asegurar que una
página o un conjunto de páginas mantienen la calidad. A un usuario
dispuesto a mantener esas páginas se le avisará en caso de
modificaciones, y así se le permitirá verificar rápidamente la
validez de las nuevas ediciones.
Vandalismo
Consiste
en realizar ediciones (generalmente hechas por desconocidos o gente
mal intencionada) que borran contenido importante, introducen
errores, agregan contenido inapropiado u ofensivo (por ejemplo,
insultos) o simplemente incumplen flagrantemente las normas del wiki.
También son frecuentes los intentos de spam, por ejemplo:
- La introducción de enlaces en un wiki con el fin de subir en los buscadores de Internet (véase PageRank).
- Los intentos de publicitarse o hacer proselitismo (de su ideología, religión u otros) a través del wiki.
- Ingresar material que viola derechos de autor.
Algunas
soluciones que se utilizan para luchar contra el vandalismo son:
- Revertir rápidamente sus cambios, para que así se desanimen.
- Bloquearlos temporalmente por su nombre de usuario o dirección IP, de tal forma que no puedan seguir editando. Esta solución se ve dificultada por las IPs dinámicas y el uso de proxies abiertos, que, al ser bloqueados, pueden afectar también a personas inocentes.
- Si se produce siempre en una misma página, la protección de esa página.
- No permitir que editen páginas usuarios que no estén registrados en la wiki.
- En casos extremos (generalmente, ataques por medio de herramientas automáticas), bloquear la base de datos del wiki, sin permitir ningún tipo de edición.
Software
Existen
varios programas, generalmente scripts de servidor en Perl o PHP, que
implementan un wiki. Con frecuencia, suelen utilizar una base de
datos, como MySQL.
Suelen
distinguirse por:
- Destino: para uso personal, para intranets, para la web, etc.
- Funcionalidad: pueden o no mantener historiales, tener opciones de seguridad, permitir subir archivos, tener editores visuales WYSIWYG, etc.
Algunos
de los más utilizados son:
- UseModWiki: el más antiguo, escrito en Perl.
- MediaWiki: utilizado en todos los proyectos de Wikimedia. Basado en PHP y MySQL.
- PhpWiki: basado en UseMod. Escrito en PHP, puede utilizar distintas bases de datos.
- TikiWiki: CMS completo, con un wiki muy desarrollado, usando PHP y MySQL.
- DokuWiki: Un wiki completo escrito en PHP sin necesidad de bases de datos (usa sólo ficheros de texto)
- WikkaWiki: basado en WakkaWiki, un wiki muy ligero. Usa PHP y MySQL
- MoinMoin: Modular. Escrito en Python.
- OpenWiking: Wiki programado en ASP.
- Swiki: Wiki programado en Squeak
Utilidades
- Pueden realizarse búsquedas en varios wikis a la vez, incluso en esta web y en la de Ward, utilizando un MetaWiki.
- El wiki es una práctica innovadora que ha expandido su uso, por ejemplo, a las empresas, las cuales utilizan este medio para que el conocimiento adquirido por los trabajadores pueda ser compartido y complementado por todos, se utiliza como una herramienta que favorece la innovación.
Blog

Los términos ingleses blog y web blog
provienen de las palabras web y log ('log' en inglés
= diario).
El web blog es una publicación en línea de
historias publicadas con una periodicidad muy alta que son
presentadas en orden cronológico inverso, es decir, lo último que
se ha publicado es lo primero que aparece en la pantalla. Es muy
frecuente que los weblogs dispongan de una lista de enlaces a otros
weblogs, a páginas para ampliar información, citar fuentes o
hacer notar que se continúa con un tema que empezó otro weblog.
También suelen disponer de un sistema de comentarios que permiten
a los lectores establecer una conversación con el autor y entre
ellos acerca de lo publicado.
Descripción
Habitualmente, en cada artículo de un blog, los
lectores pueden escribir sus comentarios y el autor darles
respuesta, de forma que es posible establecer un diálogo. No
obstante, es necesario precisar que ésta es una opción que
depende de la decisión que tome al respecto el autor del blog,
pues las herramientas permiten diseñar blogs en los cuales no
todos los internautas -o incluso ninguno- puedan participar
agregando comentarios.
El uso o tema de cada blog es particular, los hay
de tipo: periodístico, empresarial o corporativo, tecnológico,
educativo (edu blogs), políticos, personales (variados contenidos
de todo tipo) y otros muchos temas.
Historia
Antes de que los blogs se hicieran populares,
existían comunidades digitales como USENET, xrt listas de correo
electrónico, y BBS.
En los años 90, los programas para crear
foros de internet, como por ejemplo WebEx, posibilitaron
conversaciones con hilos.
Los hilos son mensajes que están relacionados con un tema del
foro.1994-2000
El blog moderno es una evolución de los diarios en
línea, donde la gente escribía sobre su vida personal, como si
fuese un diario íntimo pero dándole difusión en la red. Las
páginas abiertas Webring incluían a miembros de la comunidad de
diarios en línea. Justin Hall, quien escribió desde 1994 su blog
personal, mientras era estudiante de la Universidad de Swarthmore,
es reconocido generalmente como uno de los primeros blogueros.
También había otras formas de diarios en
línea. Un ejemplo era el diario del programador de juegos John
Carmack, publicado mediante el protocolo Finger.
Los sitios web, como los sitios corporativos y las
páginas web personales, tenían y todavía tienen a menudo
secciones sobre noticias o novedades, frecuentemente en la página
principal, y clasificados por fecha. Uno de los primeros
precursores de un blog fue el sitio web personal de Kibo,
actualizado mediante USENET.
Los primeros blogs eran simplemente componentes
actualizados de sitios web comunes. Sin embargo, la evolución de
las herramientas que facilitaban la producción y mantenimiento de
artículos web publicados y ordenados de forma cronológica, hizo
que el proceso de publicación pudiera dirigirse hacia muchas más
personas, y no necesariamente a aquellos que tuvieran conocimientos
técnicos. Últimamente, esto ha llevado a que en la actualidad
existan diversos procedimientos para publicar blogs. Por ejemplo,
el uso de algún tipo de software basado en navegador, es hoy en
día un aspecto común del blogging.
Los blogs pueden ser construidos y almacenados
usando servicios de alojamiento de blogs dedicados, o pueden ser
concretados y accedidos mediante software genérico para blogs,
como por ejemplo usando los productos Blogger o LiveJournal, o
mediante servicios de alojamiento web corrientes.
El término "weblog" fue acuñado por
Jorn Barger el 17 de diciembre de 1997. La forma corta, "blog",
fue acuñada por Peter Merholz, quien dividió la palabra weblog
en la frase we blog
en la barra lateral de su blog Peterme.com en abril o mayo de
1999.3 4 5 Y rápidamente fue adoptado tanto como nombre y verbo
(asumiendo "bloguear"
como "editar el weblog de alguien o añadir un mensaje en el
weblog de alguien").
Tras un comienzo lento, los blogs ganaron
popularidad rápidamente; el sitio Xanga, lanzado en 1996, sólo
tenía 100 diarios en 1997, pero más de 50.000.000 en diciembre de
2005. El uso de blogs se difundió durante 1999 y los siguientes
años, siendo muy popularizado durante la llegada casi simultánea
de las primeras herramientas de alojamiento de blogs:
- Open Diary lanzado en octubre de 1998, pronto creció hasta miles de diarios en línea. Open Diary innovó en los comentarios de los lectores, siendo el primer blog comunitario donde los lectores podían añadir comentarios a las entradas de los blogs.
- Brad Fitzpatrick comenzó LiveJournal en marzo de 1999.
- Andrew Smales creó Pitas.com en julio de 1999 como una alternativa más fácil para mantener una "página de noticias" en un sitio web, seguido de Diaryland en septiembre de 1999, centrándose más en la comunidad de diarios personales.
- Evan Williams y Meg Hourihan (Pyra Labs) lanzaron Blogger.com en agosto de 1999, el que fue adquirido por Google en febrero de 2003.
2000-2006
Los primeros blogs estadounidenses populares
aparecieron en 2001: AndrewSullivan.com de Andrew Sullivan,
Politics1.com de Ron Gunzburger, Political Wire de Taegan Goddardy,
MyDD de Jerome Armstrong — tratando principalmente temas
políticos.
En idioma español también aparecieron los
primeros blogs en esa época, los más destacados fueron en el año
2000 el blog llamado Terremoto.net y en el año 2001 aparecieron
Claudia-P.com, donde una adolescente de Madrid explicaba su
peculiar vida personal y El hombre que comía diccionarios.En 2002, el blogging se había convertido en tal fenómeno que comenzaron a aparecer manuales, centrándose principalmente en la técnica. La importancia de la comunidad de blogs (y su relación con una sociedad más grande) cobró importancia rápidamente. Las escuelas de periodismo comenzaron a investigar el fenómeno de los blogs, y a establecer diferencias entre el periodismo y el blogging.
En 2002, el amigo de Jerome Armstrong y ex-socio
Markos Moulitsas Zúniga comenzó DailyKos. Con picos de hasta un
millón de visitas diarias, ese espacio web se ha convertido en uno
de los blogs con más tráfico de Internet.
En el año 2006, se
escogió la fecha del 31 de agosto, para celebrar en toda la red,
el llamado "día internacional
del Blog". La idea nació de un
bloguero (usuario de blog) israelí llamado Nir
Ofir, que propuso que en esta fecha,
los blogueros que desarrollaban bitácoras personales enviaran
cinco invitaciones de cinco blogs de diferentes temáticas a cinco
diferentes contactos, para que así los internautas dieran difusión
a blogs que seguramente otras personas desconocían, y que
eventualmente les pudiera resultar interesantes.82007-presente
Hoy día el blogging es uno de los servicios de
Internet más populares. Es común que incluso cantantes y actores
famosos tengan blogs, así como también empresas internacionales.
Entre los servidores de blogs más populares se
encuentran Blogger y Wordpress.
Algunos blogueros se han ido trasladando a la
televisión y a los medios de prensa: Duncan Black, Glenn Reynolds
(Instapundit), Markos Moulitsas Zúniga (Daily Kos), Alex Steffen
(Worldchanging), Ana Marie Cox (Wonkette), Nate Silver
(FiveThirtyEight.com), y Ezra Klein (que se integró primeramente
al blog American Prospect,
después a The Washington Post).Herramientas para su creación y mantenimiento
Existen variadas herramientas de mantenimiento de blogs que permiten, muchas de ellas gratuitamente y sin necesidad de elevados conocimientos técnicos, administrar todo el weblog, coordinar, borrar, o reescribir los artículos, moderar los comentarios de los lectores, etc., de una forma casi tan sencilla como administrar el correo electrónico. Actualmente su modo de uso se ha simplificado a tal punto, que casi cualquier usuario es capaz de crear y administrar un blog personal.
Las herramientas de mantenimiento de weblogs se
clasifican, principalmente, en dos tipos: aquellas que ofrecen una
solución completa de alojamiento, gratuita (como Freewebs, Blogger
y LiveJournal), y aquellas soluciones consistentes en software que,
al ser instalado en un sitio web, permiten crear, editar, y
administrar un blog, directamente en el servidor que aloja el sitio
(como es el caso de WordPress o de Movable Type). Este software es
una variante de las herramientas llamadas Sistemas de Gestión de
Contenido (CMS), y muchos son gratuitos. La mezcla de los dos tipos
es la solución planteada por WordPress.
Las herramientas que proporcionan alojamiento
gratuito asignan al usuario una dirección web (por ejemplo, en el
caso de Blogger, la dirección asignada termina en "blogspot.com"),
y le proveen de una interfaz, a través de la cual se puede añadir
y editar contenido. Obviamente, la funcionalidad de un blog creado
con una de estas herramientas, se limita a lo que pueda ofrecer el
proveedor del servicio, o hosting.
Un software que gestione el contenido, en tanto,
requiere necesariamente de un servidor propio para ser instalado,
del modo en que se hace en un sitio web tradicional. Su gran
ventaja es que permite control total sobre la funcionalidad que
ofrecerá el blog, posibilitando así adaptarlo totalmente a las
necesidades del sitio, e incluso combinarlo con otros tipos de
contenido.
Características diferenciales de un blog (¿Qué hace de un blog, un blog?)
El éxito de los blogs se debe a que tienen una
naturaleza muy peculiar que se caracteriza, sobre todo, por tres
propiedades :
- Es una publicación periódica. Los blogs publican nuevos contenidos en periodos de tiempo relativamente cortos.
- Un blog admite comentarios de los lectores y esto hace posible que se cree una comunidad en torno al autor. Los blogs son uno de los medios que mejor representan su esencia. Gracias a la posibilidad de recibir comentarios de los lectores, se pasa de una comunicación unilateral (medio de comunicación hacia el lector) a una comunicación bilateral, en la que el lector es también protagonista. El efecto que ésta ha tenido es la creación de "comunidades" de lectores muy fieles, muy parecidas a las que existen, por ejemplo, en un foro de discusión. Esto ha resultado ser también muy ventajoso desde un punto de vista profesional o comercial porque estos lectores son personas fidelizadas que confían en el autor y, por tanto, muy abiertas a las recomendaciones e incluso venta de productos y servicios por parte del autor del blog.
- Un blog tiene un marcado toque personal. Aunque esta característica se haya diluido quizás un poco en los últimos años con la aparición de blogs corporativos y profesionales, incluso estos blogs intentan mantener un ambiente mucho más personal e informal que ayuda mucho a que se vaya forjando una relación de confianza entre el autor del blog y sus lectores, buscando mucho más la creación de un ambiente parecido al que hay entre amigos que la relación clásica entre una publicación comercial y sus lectores.
Características técnicas
Existe una serie de elementos comunes a todos los
blogs.
Comentarios
Mediante un formulario se permite, a otros usuarios
de la web, añadir comentarios a cada entrada, pudiéndose generar
un debate alrededor de sus contenidos, además de cualquier otro
intercambio de información. (Si el autor del blog lo prefiere, no
se podrán añadir comentarios a las entradas)
Enlaces
Una particularidad que diferencia a los weblogs de
los sitios de noticias, es que las anotaciones suelen incluir
múltiples enlaces a otras páginas web (no necesariamente
weblogs), como referencias o para ampliar la información agregada.
Además, y entre otras posibilidades, permite la presencia y uso
de:
- Un enlace permanente (permalink) en cada anotación, para que cualquiera pueda citarla.
- Un archivo de las anotaciones anteriores.
- Una lista de enlaces a otros weblogs seleccionados o recomendados por los autores, denominada habitualmente blogroll.
Enlaces inversos
En algunos casos las anotaciones o historias permiten que se les haga trackback, un enlace inverso (o retroenlace) que permite, sobre todo, saber que alguien ha enlazado nuestra entrada, y avisar a otro weblog que estamos citando una de sus entradas o que se ha publicado un artículo relacionado. Todos los trackbacks aparecen automáticamente a continuación de la historia, junto con los comentarios, aunque no siempre es así.Fotografías y vídeos
Es posible además agregar fotografías y vídeos a
los blogs, a lo que se le ha llamado fotoblogs o videoblogs
respectivamente.
Redifusión
Otra característica de los weblogs es la
multiplicidad de formatos en los que se publican. Aparte de HTML,
suelen incluir algún medio para redifundirlos, es decir, para
poder leerlos mediante un programa que pueda incluir datos
procedentes de muchos medios diferentes. Generalmente, para la
redifusión, se usan fuentes web en formato RSS o Atom.
Características sociales
También se diferencian en su soporte económico:
los sitios de noticias o periódicos digitales suelen estar
administrados por profesionales, mientras que los weblogs son
principalmente personales y aunque en algunos casos pueden estar
incluidos dentro de un periódico digital o ser un blog
corporativo, suelen estar escritos por un autor o autores
determinados que mantienen habitualmente su propia identidad.
Un aspecto importante de los weblogs es su
interactividad, especialmente en comparación a páginas web
tradicionales. Dado que se actualizan frecuentemente y permiten a
los visitantes responder a las entradas, los blogs funcionan a
menudo como herramientas sociales, para conocer a personas que se
dedican a temas similares, con lo cual en muchas ocasiones llegan a
ser considerados como una comunidad.
Enemigos del correcto funcionamiento de un blog
Al igual que en los foros, los principales enemigos
son el spam, los troles, y los leechers. También suelen provocar
problemas los fake (usuarios que se hacen pasar por otros
usuarios); y algunos usuarios títeres (usuarios que se hacen pasar
por varios y diferentes usuarios).
Aunque no son enemigos, los recién llegados (o
newbies) pueden ocasionar problemas en el funcionamiento del blog
al cometer errores; ya sea por no poder adaptarse rápidamente a la
comunidad, o por no leer las reglas específicas que puede tener el
blog en el que acaban de ingresar.
Otro problema es el de la lectura, producto del
lenguaje usado por los chaters.
Tipos de blogs
Hay muchos tipos diferentes de blogs, no sólo por
el contenido, sino por la forma en la que el contenido se escribe.
- Blog personal
- El blog personal, un diario en curso o un comentario de un individuo, es el blog más tradicional y común. Los blogs suelen convertirse en algo más que en una forma para comunicarse, también se convierten en una forma de reflexionar sobre la vida u obras de arte. Los blogs pueden tener una calidad sentimental. Pocos blogs llegan a ser famosos, pero algunos de ellos pueden llegar a reunir rápidamente un gran número de seguidores. Un tipo de blog personal es el micro blog, es extremadamente detallado y trata de capturar un momento en el tiempo. Algunos sitios, como Twitter, permiten a los blogueros compartir pensamientos y sentimientos de forma instantánea con amigos y familiares, y son mucho más rápidos que el envío por correo o por escrito.
- Microblogging
- Microblogging es la práctica de publicar pequeños fragmentos de contenido digital (puede ser texto, imágenes, enlaces, vídeos cortos u otros medios de comunicación) en Internet. Microblogging ofrece un modo de comunicación que para muchos es orgánica y espontánea y captura la imaginación del público. Lo utilizan amigos para mantenerse en contacto, socios de negocios para coordinar las reuniones o compartir recursos útiles, y las celebridades y políticos para las fechas de sus conciertos, conferencias, lanzamientos de libros u horarios de viajes. Una amplia y creciente gama de herramientas adicionales permite actualizaciones complejas y la interacción con otras aplicaciones, y la profusión resultante de la funcionalidad está ayudando a definir nuevas posibilidades para este tipo de comunicación.
- Blogs corporativos y organizacionales
- Un blog puede ser privado, como en la mayoría de los casos, o puede ser para fines comerciales. Los blogs que se usan internamente para mejorar la comunicación y la cultura de una sociedad anónima o externamente para las relaciones de marketing, branding o relaciones públicas se llaman blogs corporativos. Blogs similares para los clubes y sociedades se llaman blogs de club, blogs de grupo o por nombres similares; el típico uso consiste en informar a los miembros y a otras partes interesadas sobre las fiestas del club y las actividades de sus miembros.
- Blogs educativos
- Un blog educativo está compuesto por materiales, experiencias, reflexiones y contenidos didácticos, que permite la difusión periódica y actualizada de las actividades realizadas en la escuela. Los blogs educativos permiten al profesorado la exposición y comunicación entre la comunidad educativa y el alumnado, potenciando un aprendizaje activo, crítico e interactivo.
- Por el género
- Algunos blogs se centran en un tema particular, como los blogs políticos, blogs de salud, blogs de viajes (también conocidos como Cuadernos de viaje), blogs de jardinería, blogs de la casa, blogs de moda, blogs de proyectos educativos, blogs de música clásica, blogs de esgrima, blogs jurídicos, etc. Dos tipos comunes de blogs de género son los blogs de música y los blogs de arte. A los blogs con discusiones especialmente sobre el hogar y la familia no es infrecuente llamarlos blogs mamá, y este tipo de blogs se hizo popular por Erica Diamond, creadora de Womenonthefence.com, que es seguido por más de dos millones de lectores mensuales. Aunque no es un tipo legítimo de blog, ya que se utiliza con el único propósito de hacer spams, se conoce como un Splog.
- Por el tipo de medios de comunicación
- Un blog que incluye vídeos se llama vlog, uno que incluye enlaces se denomina linklog, un sitio que contiene un portafolio de bocetos se llama sketchblog, u otro que incluye fotos se llama fotolog. Los blogs con mensajes cortos y con tipos de medios mixtos se llaman tumblelogs. Aquellos blogs que se redactan en máquinas de escribir y luego son escaneados, se denominan blogs typecast. Un tipo raro de blog incluido en el protocolo Gopher es conocido como un Phlog.
- Por el dispositivo
- Los blogs también pueden diferenciarse por el tipo de dispositivo que se utiliza para construirlo. Un blog escrito por un dispositivo móvil como un teléfono móvil o una PDA podría llamarse moblog. Uno de los blogs más nuevos es el Wearable Wireless Webcam, un diario en línea compartido de la vida personal de una persona, que combina texto, vídeo e imágenes transmitidas en directo desde un ordenador portátil y un dispositivo Eye Tap a un sitio web. Esta práctica semi-automatizada de blogs con vídeo en directo junto con el texto se conoce como sub-supervisión. Estas revistas se han utilizado como pruebas en asuntos legales.
- Blog inversa
- Este blog está compuesto por sus usuarios en lugar de un solo bloguero. Este sistema tiene las características de un blog y la escritura de varios autores. Estos blogs pueden estar escritos por varios autores que han contribuido en un tema o que han abierto uno para que cualquiera pueda escribir. Normalmente hay un límite para el número de entradas, para evitar que se opere como un foro de Internet.
Taxonomía
Algunas variantes del weblog son los openblog,
fotolog, los vlogs (videoblogs), los audioblogs y los moblog (desde
los teléfonos móviles). Además, cada vez son más los weblogs
que incorporan podcast como sistema adicional de información u
opinión.
Hispanización de la palabra
Muchas personas denominan bitácora a una bitácora de red o blog, haciendo referencia a la idea de llevar un registro cronológico de sucesos, contando cualquier historia o dándole cualquier otro uso (posiblemente influidos por el uso del término que se hace en la serie de ciencia ficción Star Trek para aludir al diario de a bordo del capitán de la nave).En el año 2005 la Real Academia Española introdujo el vocablo en el Diccionario Panhispánico de Dudas 10 con el objeto de someterlo a análisis para su aceptación como acepción y su posterior inclusión en el Diccionario.
Glosario
- Entrada, entrega, posteo o asiento: la unidad de publicación de una bitácora. En inglés se le llama "post" o "entry".
- Borrador: es una entrada ingresada al sistema de publicación, pero que todavía no se ha publicado. Generalmente se opta por guardar una entrada como borrador cuando se piensa corregirla o ampliarla antes de publicarla. En inglés se le llama "draft".
- Fotolog o fotoblog: unión de foto y blog, blog fotográfico.
- Videolog o videoblog: concepto similar al anterior que nace de la unión de vídeo y blog, blog con clips de vídeo, típicamente usando reproductores embebidos de sitios conocidos como YouTube o Vimeo.
- Permalink: enlace permanente. Es el URI único que se le asigna a cada entrada de la bitácora, el cual se debe usar para enlazarla. Un permalink es un enlace permanente. Se usa en los blogs para asignar una URL permanente a cada entrada del blog, para luego poder referenciarla.
- Bloguero: escritor de publicaciones para formato de blog. Es común el uso del término inglés original: "blogger".
- Comentarios: son las entradas que pueden hacer los/as visitantes del blog, donde dejan opiniones sobre la nota escrita por el/la autor/a. En inglés se le llama "comments".
- Plantilla o tema: documento que contiene pautas de diseño pre-codificado de uso sencillo. En inglés se le llama "template". Estas plantillas, que habitualmente utilizan hojas de estilo en cascada -CSS-, pueden ser modificadas en la mayoría de los casos por los propios usuarios y adaptadas a sus necesidades o gustos.
- Plugin: complemento similar a las usadas, por ejemplo, en navegadores web para ampliar la funcionalidad del productos. No todas las plataformas permiten el uso de plugins. El productos líder del mercado, WordPress.org, cuenta en este momento (2013) con más de 25.000 plugins en su repositorio oficial11 .
- Bloguear: acción de publicar mensajes en weblogs.
- Blogonimia: Investigación del origen de los nombres con que los blogueros o dueños de las bitácoras han bautizado sus blogs. El término fue usado por primera vez en el blog eMe.
- Blogalifóbico: calificativo que se aplica a aquellas empresas u organizaciones que no aceptan que sus empleados tengan blogs. Como la palabra indica, sería una fobia a los blogs. Se sustenta en el miedo a que en el blog aparezcan informaciones que puedan dañar la imagen de una empresa, o que perjudiquen a sus beneficios...
- Tumblelog:
blog de apuntes, esbozos, citas o enlaces sin exigencias de
edición, ni completitud. No admiten comentarios, etiquetas o
categorías. Tienen un aire neoweb 1.0.
Comunidad y catalogación
- La Blogosfera
- La comunidad colectiva de todos los blogs se conoce como la blogosfera. Dado que todos los blogs están en Internet, por definición pueden ser vistos como interconectados y socialmente en red, a través de blogroll, comentarios, LinkBacks y vínculos de retroceso. Las discusiones en "la blogsfera" ocasionalmente son utilizadas por los medios como un indicador de la opinión pública sobre diversos temas. Debido a nuevas comunidades, sin explotar de los blogueros y sus lectores pueden emerger en poco tiempo, los comerciantes de Internet que prestaran mucha atención a las "tendencias de la blogosfera".
- Motores de búsqueda
- Varios motores de búsqueda de blogs se utilizan para buscar los contenidos del blog, tales como Bloglines, BlogScope y Technorati. Technorati, uno de los motores de búsqueda más populares de blogs, proporciona información actualizada sobre las dos búsquedas más populares y etiquetas para categorizar entradas de blog. La comunidad de investigadores está trabajando en ir más allá de la búsqueda por una palabra clave simple, inventando nuevas maneras de navegar a través de una enorme cantidad de información presente en la blogosfera, como lo demuestran proyectos como BlogScope.
- Comunidades de blogs y directorios
- Existen varias comunidades en línea que conectan a la gente a los blogs y a los blogueros con otros blogueros, incluyendo BlogCatalog y MyBlogLog. También están disponibles los intereses específicos de las plataformas de los blogs. Por ejemplo, Blogster tiene una considerable comunidad de políticos blogueros entre sus miembros. Global Voices agrega a blogueros internacionales, "poniendo el énfasis sobre las voces que generalmente no son oídas en medios de comunicación internacionales establecidos."
- Los blogs y la publicidad
- Es común para los blogs destacar cualquier publicidad para beneficiar económicamente al bloguero o para promover causas favoritas del bloguero. La popularidad de los blogs ha dado lugar a los "blogs falsos". Estos son aquellos blogs de ficción que crean las empresas como herramienta de marketing para promocionar un producto.
Uso en comunidades
El método de publicación que usan los weblogs se
ha vuelto tan popular que se usa en muchas comunidades, sólo para
manejo de noticias y artículos, donde no sólo participa uno, sino
varios autores, aportando artículos a la comunidad.
Las comunidades son personas con un interés común
como puede ser la cocina, el cine, el deporte, la historia o
cualquier otro tema que las identifique. A través de blogs
temáticos estas comunidades comparten recetas de comidas, noticias
sobre estrenos de películas, resultados deportivos, nuevos
descubrimientos científicos, o eventos, entre otros.
Popularidad
Los investigadores han analizado la manera de cómo
los blogs se hacen populares. Fundamentalmente, hay dos medidas
para esto: la popularidad a través de citas, así como la
popularidad a través de la afiliación (es decir el blogroll). La
conclusión básica de los estudios de la estructura de los blogs
es que, si se necesita tiempo para que un blog sea popular a través
del blogroll, permalinks puede aumentar la popularidad más
rápidamente, y tal vez son más indicativos sobre la popularidad y
autoridad que los blogrolls, ya que indican que las personas
relamente leen el contenido del blog y lo consideran valioso y
digno de mención en casos específicos.
El proyecto de blogdex fue lanzado por
investigadores en el Laboratorio de Medios de comunicación MIT
para avanzar lentamente en la Web y juntar datos de unos miles de
blogs para analizar sus propiedades sociales. Esta información se
fue juntando durante más de 4 años, y autónomamente rastreó la
información más contagiosa que se extiende en la comunidad del
blog, alineándolo por la popularidad y la novedad. Por lo tanto
este puede ser considerado como la primera creación de ejemplares
de memetracker. El proyecto fue sustituido por tailrank.com que a
su turno ha sido sustituido por spinn3r.com.
La clasificación de los blogs a través de
Technorati está basada en el número de enlaces entrantes y la de
Alexa Internet en los éxitos de Internet de usuarios de Alexa
Toolbar. En agosto de 2006, Technorati encontró que el blog más
vinculado en Internet era el de la actriz china Xu Jinglei. El
medio de comunicación chino Xinhua, divulgó que este blog recibió
más de 50 millones de visitas, reclamándolo para ser el blog más
popular del mundo. Technorati tasó Boing Boing para ser el
blog/grupo escrito más leído.
Clasificación según la influencia
Según el buscador de blogs Wikio, los cinco blogs más influyentes del mundo en enero de 2008 fueron TechCrunch, Mashable!, Engadget, Gizmodo y Boing Boing.El blog en español más influyente fue, de acuerdo con esta clasificación, Microsiervos (España), situado en la décimo tercera posición. Entre los veinte blogs más influyentes de Europa, existían cinco blogs de España, todos en castellano: Microsiervos (2ª posición), Mangas Verdes (6ª), Genbeta (7ª), Loogic (19ª) y Error 500 (20ª). A nivel exclusivamente de habla hispana, según la clasificación de Alianzo,13 los blogs más influyentes en español son los siguientes: Microsiervos (España), Barrapunto (España), Enrique Dans (España), Alt1040 (México), genbeta (España), Dirson (España), FayerWayer (Chile), Kriptópolis (España), Escolar.net (España) y Denken Über (Argentina).Confusión con los medios de comunicación
Muchos blogueros, especialmente aquéllos que se
dedican al periodismo participativo, se diferencian de los medios
de comunicación establecidos, mientras que otros son miembros de
aquellos medios de comunicación a través de otro canal diferente.
Algunas instituciones ven el blog como un medio para "moverse
por el filtro" y que empuja mensajes directamente al público.
Algunos críticos de preocupan de que algunos blogueros no respetan
los derechos de autor ni los medios de comunicación en la sociedad
con la presentación de noticias creíbles. Los blogueros y otros
contribuyentes al contenido generado por usuarios están detrás de
la revista Time 2006 nombrando a su personaje del año como
"Usted".
Por su parte, muchos periodistas tradicionales
escriben sus propios blogs. El primer uso conocido de un blog en un
sitio de noticias fue en agosto de 1998, cuando Jonathan Dube de la
Charlotte Observer publicó una crónica del huracán Bonnie.
Algunos blogueros se han trasladado a otros medios
de comunicación. Los blogueros siguientes (y otros) han aparecido
en la radio y en la televisión: Duncan Black (conocido por su
alias, Atrios), Glenn Reynolds (Instapundit), Markos Moulitsas
Zúniga(Daily Kos), Alex Steffen (Worldchanging), Ana Marie Cox
(Wonkette), Nate Silver (FiveThirtyEight.com), and Ezra Klein (el
blog de Ezra Klein en The American Prospect, hoy en el diario de
Washington Post). En contrapunto, Hugh Hewitt es un ejemplo de una
personalidad de los medios de masas que se ha movido en la
dirección opuesta, añadido en su alcance a los "viejos
medios de comunicación" por ser un bloguero muy influyente.
Del mismo modo, fue Preparativos para Emergencias y Consejos de
Seguridad en el Aire y artículos de blog en línea que capturó la
atención del Director General de Sanidad de los EEUU Richard
Carmona y ganó sus felicitaciones por sus emisiones asociadas con
el locutor Tolliver Lisa y Westchester Emergency Volunteer
Reserves-Medical Reserve Corps Director Marianne Partridge.
Los blogs también han tenido influencia en las
lenguas minoritarias, juntando a hablantes dispersos y alumnos; lo
que es particularmente cierto con las lenguas gaélicas. La
industria editorial de las lenguas minoritarias (que puede carecer
de viabilidad económica) puede encontrar a su audiencia a través
de blogs baratos.
Hay muchos ejemplos de blogueros que han publicado
libros basados en sus blogs, por ejemplo, Salam Pax, Ellen
Simonetti, Cutler Jessica, ScrappleFace. A los blogs basados en
libros se les ha dado el nombre de blook. Un premio para el mejor
blog basado en un libro se inició en 2005, el Premio Lulu Blooker.
Sin embargo, el éxito ha sido esquivo, con muchos libros no
vendidos. Solo el bloguero Tucker Max hizo el New York Times
Bestseller List. El libro basado en el blog de Julie Powell, El
Proyecto Julie, se convirtió en la película Julie &
Julia, aparentemente el primero en hacerlo.
No hay comentarios.:
Publicar un comentario